DirectX 12 (DX12) es una API de bajo nivel para trabajar con la tarjeta gráfica.
UE4 y otros motores de videojuegos, como Unity, usan DirectX12 por debajo.
DX12 no es el único jugador en cuanto a APIs gráficas de bajo nivel se refiere. También tenemos a Vulkan. Ambas APIs comparten la mayoría de conceptos. No en vano, al ser APIs de muy bajo nivel, *casi* le estás hablando directamente a la GPU por lo que manejarás en ambas APIs conceptos propios del uso interno de la GPU.
Si empiezas con DX12 el salto a Vulkan será pequeño y viceversa.
Saber como funciona estas APIs te proporciona un conocimiento valiosísimo de como funcionan los motores de videojuegos detrás de las cortinas.
Esta serie de tutoriales son muy técnicos y no están relacionados con UE4 más que lo pueden estar con Unity u otro motor.
¿Qué vamos a ver?
El objeto de esta serie de tutoriales será crear un ejemplo sencillo de un cubo texturizado que gire sobre sí mismo.
A pesar de la sencillez del ejemplo, tendrás que poner encima de la mesa todos los conceptos importantes de DX12.
Requisitos
Es importante tener amplios conocimientos de C++.
Puedes acceder a una guía rápida y concisa para programadores aquí.
En esta serie de tutoriales no vamos a hablar de shaders aunque escribiremos algunos muy básicos. Si no tienes ni idea de como se programa un shader quizás debas echarle antes un vistazo a una guía rápida de HLSL. Te bastará con saber lo más básico.
También debes tener conocimientos previos de producción 3D.
Ayudaría saber algo de álgebra lineal: matrices y vectores. Si no, es posible que te pierdas en tutoriales venideros.
Tabla de contenidos
Window
En este primer tutorial vamos a crear una ventana en windows y preparar las librerías para usar DX12.
Abre Visual Studio y cree un proyecto vacío en C++. Llámalo BoxDemo.
Librerías
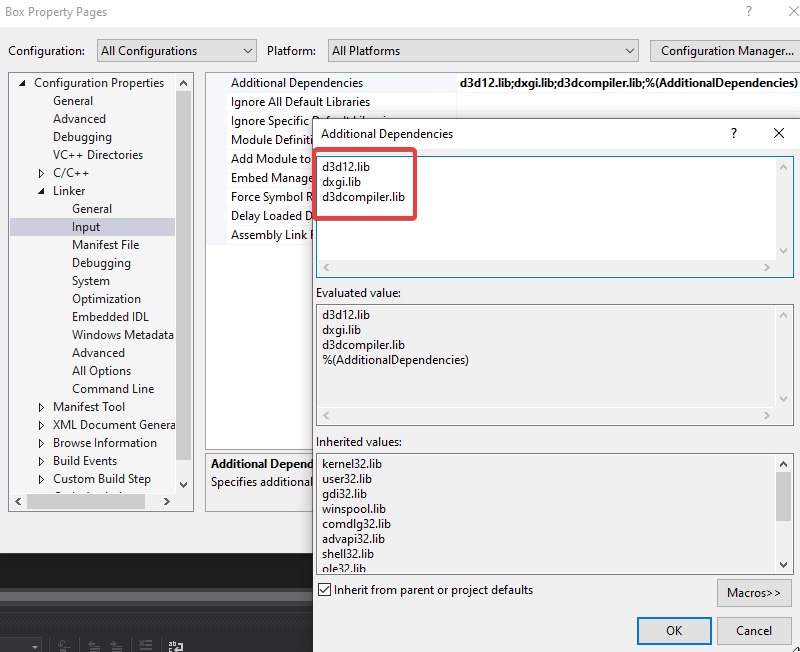
Añade las siguientes librerías al proyecto:
d3d12.lib
dxgi.lib
d3dcompiler.lib
user32.libSegún tu versión de Visual Studio quizás user32.lib ya está incluido.
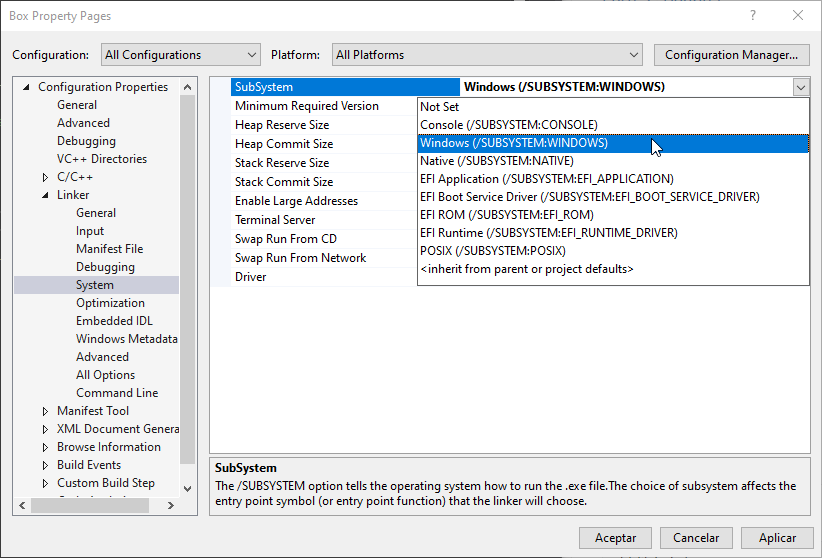
El punto de entrada de un proyecto Windows es el método WinMain (frente al método main de un proyecto consola). Hay que indicárselo al compilador:
Cree un fichero main.cpp y añade el siguiente código:
// include Windows header
#define WIN32_LEAN_AND_MEAN
#include <windows.h>
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE, LPSTR, int nCmdShow)
{
return 0;
}Debería compilar y ejecutarse sin problemas.
Vamos ahora a crear la ventana.
Crear una ventana
Crear una ventana es relativamente fácil.
Los pasos son:
- Declarar una función que será la encargada de gestionar los eventos que ocurren en la ventana, por ejemplo si se ha cerrado, minimizado, etc.,
- Registrar un WNDCLASSEX que es una estructura que contiene el título de la ventana, el icono, el menú, etc., a esta estructura le pasaremos la función del paso 1.
- Crear una ventana usando la estructura anterior.
- Mostrar la ventana.
- En un bucle infinito preguntar a Windows si tenemos eventos pendientes para procesar. Si tenemos eventos pendientes lo "distribuimos" a la función del paso 1.
El código sería el siguiente:
#define WIN32_LEAN_AND_MEAN
#include <windows.h>
static const LPCTSTR WindowClassName = L"DirectXTest";
static const LPCTSTR WindowTitle = L"aprendeunrealengine.com";
static const int Width = 800;
static const int Height = 600;
// Paso 1: Declarar una función que será la encargada de gestionar los eventos
LRESULT CALLBACK WndProc(HWND hWnd, UINT Message, WPARAM wParam, LPARAM lParam);
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE, LPSTR, int nCmdShow)
{
// Paso 2: Registrar una estructura WNDCLASSEX
WNDCLASSEX WindowClass;
WindowClass.cbSize = sizeof(WNDCLASSEX);
WindowClass.style = CS_HREDRAW | CS_VREDRAW;
WindowClass.lpfnWndProc = WndProc; // pasarle la función
WindowClass.cbClsExtra = NULL;
WindowClass.cbWndExtra = NULL;
WindowClass.hInstance = hInstance;
WindowClass.hIcon = LoadIcon(NULL, IDI_APPLICATION);
WindowClass.hCursor = LoadCursor(NULL, IDC_ARROW);
WindowClass.hbrBackground = (HBRUSH)COLOR_WINDOW;
WindowClass.lpszMenuName = NULL;
WindowClass.lpszClassName = WindowClassName;
WindowClass.hIconSm = LoadIcon(NULL, IDI_APPLICATION);
// Registrar la estructura
if (!RegisterClassEx(&WindowClass))
{
OutputDebugString(L"[ERROR] !RegisterClassEx(&WindowClass)");
return 1;
}
// Paso 3. Crear una ventana usando la estructura anterior.
// devuelve un handle que identifica la ventana creada.
HWND hWnd = CreateWindowEx(
NULL, // dwExTyle
WindowClassName, // ClassName
WindowTitle, // WindowTitle
WS_OVERLAPPEDWINDOW, // dwStyle
CW_USEDEFAULT, CW_USEDEFAULT, // (X, Y)
Width, Height, // (Width, Height)
NULL, // WndParent
NULL, // Menu
hInstance, // hInstance
NULL // lpParam
);
if (!hWnd)
{
OutputDebugString(L"[ERROR] !CreateWindowEx");
return 1;
}
// Paso 4. Mostrar la ventana
ShowWindow(hWnd, nCmdShow);
UpdateWindow(hWnd);
// Paso 5. Preguntar a Windows por eventos.
// los eventos se llaman mensajes en windows.
MSG Message; ZeroMemory(&Message, sizeof(Message));
// bucle infinito para preguntar por eventos
while (true)
{
// conseguir el evento y eliminarlo de la cola de eventos
if (PeekMessage(&Message, NULL, 0, 0, PM_REMOVE))
{
if (Message.message == WM_QUIT)
{
break;
}
}
// distribuir el evento para que podamos procesarlo en WndProc.
TranslateMessage(&Message);
DispatchMessage(&Message);
}
}
LRESULT CALLBACK WndProc(HWND hWnd, UINT Message, WPARAM wParam, LPARAM lParam)
{
switch (Message)
{
case WM_KEYDOWN:
{
if (wParam == VK_ESCAPE)
{
DestroyWindow(hWnd);
}
return 0;
}
case WM_DESTROY:
{
PostQuitMessage(0);
return 0;
}
default:
{
// si no procesamos el evento, se lo pasamos al gestor por
// defecto que trae Windows
return DefWindowProc(hWnd, Message, wParam, lParam);
}
}
}No hay mucho que discutir aquí. Así es como funciona la API de Microsoft y las llamadas que debes hacer para tener una ventana por pantalla.
Faltaría por implementar WndProc.
LRESULT CALLBACK WndProc(HWND hWnd, UINT Message, WPARAM wParam, LPARAM lParam)
{
switch (Message)
{
case WM_KEYDOWN:
{
if (wParam == VK_ESCAPE)
{
DestroyWindow(hWnd);
}
return 0;
}
case WM_DESTROY:
{
PostQuitMessage(0);
return 0;
}
default:
{
// si no procesamos el evento, se lo pasamos al gestor por
// defecto que trae Windows
return DefWindowProc(hWnd, Message, wParam, lParam);
}
}
}El resultado final sería:
Siguiente paso
Teniendo la ventana en funcionamiento, vamos a empezar a hacer uso de la API de DX12.
Adapter
Necesitamos comunicarnos con la tarjeta gráfica para enviarle trabajo y copiar recursos (como texturas y otros).
Para ello necesitamos enumerar que tarjetas gráficas compatibles con DirectX tenemos disponibles en el sistema. Escoger una de ellas y crear una interfaz para comunicarnos.
Objetivo
El objetivo de este tutorial será escoger una tarjeta gráfica y crear una interfaz para poder comunicarnos con ella.
Antes de nada algunos apuntes sobre pequeñas peculiaridades de C++ con DirectX12.
C++ en DirectX 12
DX12 es una API que expone su API (clases y objetos) a través de objetos COM. No necesitamos saber qué es un objeto COM ni como funcionan. Lo único importante es que Microsoft recomienda usar ComPtr para tratar con ellos.
Es decir, en vez de usar un puntero a secas:
ID3D12Device* MyDevice;
MyDevice->MetodosPropiosDeDevice(...)Envolverlo con ComPtr:
ComPtr<ID3D12Device> MyDevice;
// ComPtr<T> expone con "->" los métodos de T
// así que no hay ninguna diferencia en sintaxis
// en usar ComPtr<T> ó T* lo cual es muy conveniente
MyDevice->MetodosPropiosDeDevice(...);
// si en algún momento necesitaramos el puntero a secas:
ID3D12Device* MyDevice = MyDevice.Get();¿Qué es ComPtr? Es un puntero inteligente. Mantiene un contador de las referencias que se hacen al objeto y cuando llega a cero, lo libera.
ComPtr<T> es equivalente a un shared_ptr<T>.
¿No sabes que es shared_ptr<T> en C++? Aquí tienes una guía rápida de C++ para programadores.
En DX12 la forma de crear objetos objetos suele ser:
- Rellenar una estructura de la forma D3D12_xxxxx_DESC
- Pasar la estructura anterior a una función de la forma D3D12CreateXXXXX
Esta forma de crear objetos la veremos a todas horas y en todos sitios.
Las funciones de la forma CreateXXXX devuelven el objeto creado como argumento de salida. También necesitan el tipo.
// Aquí vamos a almacenar una referencia al objeto creado
ComPtr<IDXGIFactory4> Factory;
// Ejemplo de función CreateXXXX
CreateDXGIFactory1(
_uuidof(IDXGIFactory4), // tipo
&Factory // argumento de salida
);Dado que es muy engorroso tener que escribir constantemente el tipo y el argumento de salida, se hace uso de la macro IID_PPV_ARGS:
ComPtr<IDXGIFactory4> Factory;
CreateDXGIFactory1(
IID_PPV_ARGS(&Factory) // esta macro se expande con el tipo y argumento
);Por último, las funciones devuelven un tipo HRESULT indicando si la llamada ha sido exitosa o no.
Existen macros como SUCCEEDED y FAILED para comprobar un HRESULT:
HRESULT hr = CreateDXGIFactory1(
IID_PPV_ARGS(&Factory) // esta macro se expande con el tipo y argumento
);
if (FAILED(hr))
{
DebugLog("Imposible crear una Factory1");
return false;
}La aplicación
Crea una nueva clase llamada DemoApp dónde programaremos nuestra aplicación.
// DemoApp.h
#pragma once
// ComPtr<T>
#include <wrl.h>
using namespace Microsoft::WRL;
// DirectX 12 specific headers.
#include <d3d12.h> // D3D12xxxx
#include <dxgi1_6.h> // factories
#include <d3dcompiler.h> // compilar shaders
#include <DirectXMath.h> // matematicas
class DemoApp
{
public:
DemoApp();
};Esta clase será llamada por main.cpp en su momento.
Punto de entrada
El punto de entrada de DX12 es IDXGIFactory4.
Gracias a esta clase podremos enumerar los adaptores (tarjetas gráficas compatibles con DX12) y elegir un adaptador.
Añade un miembro IDXGIFactory4 a la clase DemoApp.
// DemoApp.h
class DemoApp
{
public:
DemoApp();
private:
ComPtr<IDXGIFactory4> Factory;
};
// DemoApp.cpp
DemoApp::DemoApp()
{
CreateDXGIFactory1(IID_PPV_ARGS(&Factory));
}Los números que aparecen como sufijo en CreateDXGIFactory y otras funciones del estilo CreateXXXXX están relacionados con los cambios en la firma de la función, no en la interfaz devuelva por la función.
Enumerar los adapters
Un adaptor es el nombre que se le ha dado en DX12 a los dispositivos instalados en el sistema compatibles con la API (tarjetas gráficas sobre todo).
Cada adaptador tiene asociado un índice. Puedes obtener el adaptador con índice AdapterIndex así:
ComPtr<IDXGIAdapter1> Adapter;
HRESULT result = Factory->EnumAdapters1(AdapterIndex, &Adapter);
if (result != DXGI_ERROR_NOT_FOUND)
{
// En Adapter tenemos el adaptador con índice AdapterIndex
// podemos pedirle info como su nombre, memoria, etc.,
DXGI_ADAPTER_DESC1 AdapterDesc;
Adapter->GetDesc1(&AdapterDesc);
// AdapterDesc.Description --- nombre, por ejemplo NVIDIA GTX 970
// Más campos como AdapterDesc.DedicatedVideoMemory, etc.,
}Para enumerar todos los adaptadores:
ComPtr<IDXGIAdapter1> Adapter;
bool bAdapterFound = false;
for (UINT AdapterIndex = 0;
!bAdapterFound && Factory->EnumAdapters1(AdapterIndex, &Adapter) != DXGI_ERROR_NOT_FOUND;
++AdapterIndex)
{
DXGI_ADAPTER_DESC1 AdapterDesc;
Adapter->GetDesc1(&AdapterDesc);
// que este adaptador no sea emulado por software
if (AdapterDesc.Flags & DXGI_ADAPTER_FLAG_SOFTWARE)
{
continue;
}
// decidir con bAdapterFound si es este adaptador el que queramos
}Device
Una vez encontrado el adaptador podemos crear un dispositivo ID3D12Device.
Un ID3D12Device es una interfaz que nos permite comunicarnos con la tarjeta gráfica:
- enviarle trabajo,
- reservar espacio de memoria,
- copiar recursos,
- etc.,
Podemos crear un ID3D12Device a través de un adaptador usando el método:
ComPtr<IDXGIAdapter1> Adapter;
// ... seleccionar el Adapter con el código anterior ...
ComPtr<ID3D12Device> Device;
D3D12CreateDevice(Adapter.Get(), D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&Device));La constante D3D_FEATURE_LEVEL_11_0 indica que el dispositivo debe ser compatible con DirectX12.
¿Qué ocurre si el adaptador que hemos escogido no es compatible con DX12? Entonces la función devolverá un error:
HRESULT hr;
hr = D3D12CreateDevice(Adapter.Get(), D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&Device));
if (FAILED(hr))
{
// ¡no es compatible con DirectX12!
}De hecho, si sólo queremos preguntar por la compatibilidad, podemos dejar a nullptr el argumento de salida:
hr = D3D12CreateDevice(Adapter.Get(), D3D_FEATURE_LEVEL_11_0, _uuidof(ID3D12Device), nullptr);
Con todo lo dicho, el código quedaría:
// DemoApp.h
class DemoApp
{
public:
DemoApp();
private:
ComPtr<IDXGIFactory4> Factory;
ComPtr<ID3D12Device> Device;
};
// DemoApp.cpp
DemoApp::DemoApp()
{
CreateDXGIFactory1(IID_PPV_ARGS(&Factory));
ComPtr<IDXGIAdapter1> Adapter;
bool bAdapterFound = false;
for (UINT AdapterIndex = 0;
!bAdapterFound && Factory->EnumAdapters1(AdapterIndex, &Adapter) != DXGI_ERROR_NOT_FOUND;
++AdapterIndex)
{
DXGI_ADAPTER_DESC1 AdapterDesc;
Adapter->GetDesc1(&AdapterDesc);
if (AdapterDesc.Flags & DXGI_ADAPTER_FLAG_SOFTWARE)
{
continue;
}
HRESULT hr;
hr = D3D12CreateDevice(Adapter.Get(),
D3D_FEATURE_LEVEL_11_0,
_uuidof(ID3D12Device),
nullptr);
if (SUCCEEDED(hr))
{
bAdapterFound = true;
}
}
D3D12CreateDevice(Adapter.Get(),
D3D_FEATURE_LEVEL_11_0,
IID_PPV_ARGS(&Device));
}Recuerda hacer uso de la clase en main.cpp
// ...
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE, LPSTR, int nCmdShow)
{
// ...
DemoApp App;
// bucle infinito para preguntar por eventos
while (true)
{
// ...
}
}Capa de depuración
DX12 es API muy liviana que no supone apenas un "sobrecoste". La contrapartida es que no disponemos de información de depuración por si hemos metido la pata con algún parámetro o ajuste.
En entornos de desarrollo es muy útil activar la capa de depuración de DX12 que te avisará de potenciales errores.
La capa de depuración se activa en el punto de entrada de la API: DXGIFactory.
ComPtr<ID3D12Debug> DebugController;
if (SUCCEEDED(D3D12GetDebugInterface(IID_PPV_ARGS(&DebugController))))
{
DebugController->EnableDebugLayer();
}
CreateDXGIFactory2(DXGI_CREATE_FACTORY_DEBUG, IID_PPV_ARGS(&Factory));Siguientes pasos
Ya tenemos acceso a la tarjeta gráfica con ID3D12Device. Ya es hora de ponerla a trabajar.
Conceptos
En la parte anteriorde esta serie de tutoriales pudimos tener una primera toma de contacto con la API y creamos un dispositivo.
Ahora podemos comunicarnos con la GPU para que haga "cosas". Pero... ¿qué cosas?
DX12 es una API de muy bajo nivel por lo que antes de seguir avanzando hay que tener claros algunos conceptos fundamentales sobre cómo funciona la GPU.
Pipeline
Para renderizar un frame la GPU sigue una secuencia de etapas:
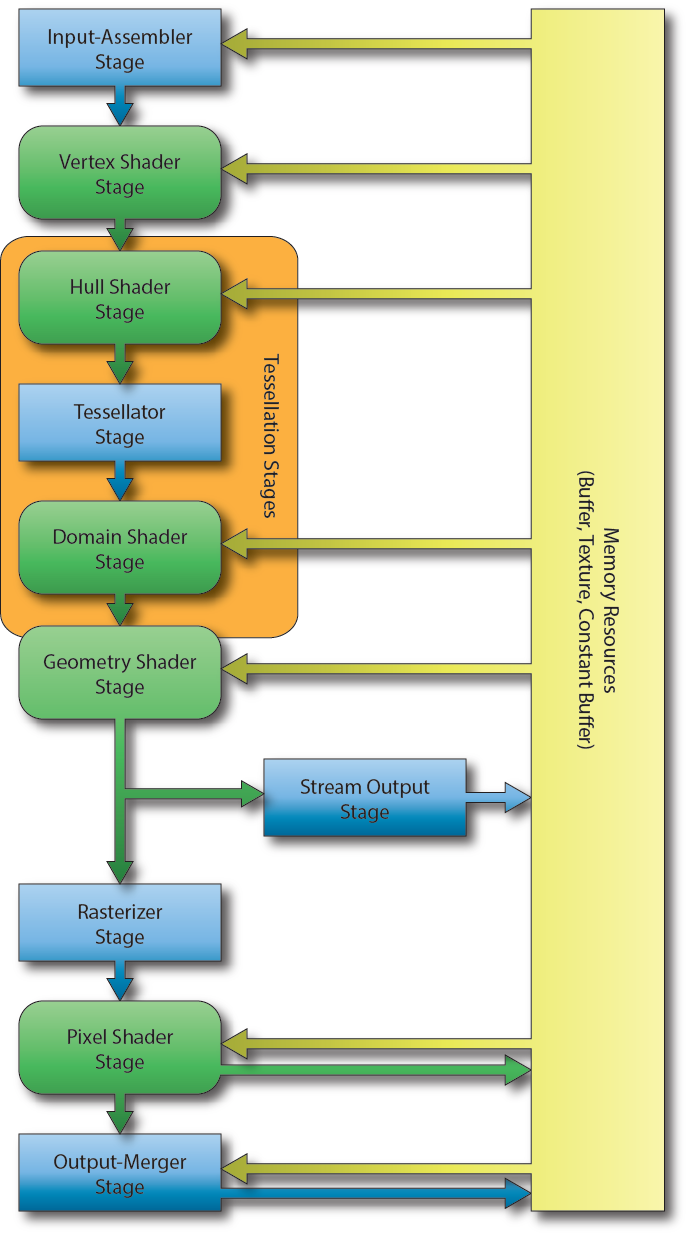
Al conjunto de estas etapas se le suele denominar Pipeline. Las salidas de una etapa son las entradas de la siguiente.
Las etapas en color verde son programables, esto es, le enviaremos a la GPU un programa (escrito en lenguaje GLSL) para que lo ejecute en dicha etapa. A estos programas se les denomina shaders.
El resto de etapas, de color azul, son etapas fijas no-programables. Podemos, y debemos, ajustar algunos parámetros de estas etapas fijas.
Algunas etapas son opcionales. En concreto las etapas referentes a la teselación y Geometry Shader.
La salida del pipeline es la salida de su última etapa, esto es, la etapa Output Merger. Se trata de una textura (imagen 2D) con la escena renderizada. A esta textura se le denomina Render Target.
La primera entrada, en concreto la entrada de Input Assembler, es un conjunto de vértices.
Los vértices, en general, no solo contienen una posición, también pueden contener datos adicionales como color, coordenadas UV, normales, etc., a este conjunto de vértices se le denomina Vertex Buffer.
Entre los parámetros que podemos configurar en la etapa Input Assembler está cómo interpretar los vertex buffer, ¿te pinto cada vértice como un punto? ¿o interpreto cada tres vértices como un triángulo? Normalmente se usa esta última.
El Input Assembler, además del Vertex Buffer, también puede tener como entrada un Index Buffer.
El Index Buffer se usa para reutilizar los vértices del Vertex Buffer.
Piensa en un cubo, para pintar cada triángulo del cubo necesitaríamos: 2 triángulos por 3 vértices por triángulo por 6 caras del cubo = 36 vértices.
Sin embargo, sería más conveniente definir en el Vertex Buffer únicamente los 8 vértices del cubo y con un Index Buffer referenciarlos para pintar las caras.
Uno de los objetivos con DirectX 12 es configurar apropiadamente el pipeline.
Es decir, subir los shaders a las etapas programables y configurar los parámetros deseados en las etapas fijas. Veremos como hacerlo en siguientes tutoriales.
Cualquier etapa puede usar recursos adicionales de la memoria de la GPU. En concreto las etapas programables, en general, necesitarán recursos de la memoria como texturas, matrices, vectores, etc.
Colas de comandos
La GPU mantiene una cola de comandos. Un comando es una orden que se le da a la GPU como:
- Borra la textura con este color
- Pon este render target como salida al Output Merger
- Pon este vertex buffer como entrada a este Input Assembler
- Reconfigura todo el pipeline con estos nuevos parámetros
- Cambia el estado de un recurso de leíble a escribible
- Copia este recurso de este espacio de memoria a este otro
- etc.,
Estos comandos son encolados en una cola y la GPU los irá ejecutando.
Tendrás que crear una interfaz para la cola de comandos y así poder enviarle comandos a la GPU. Lo veremos.
Sincronizar CPU / GPU
La CPU y la GPU son dos dispositivos independientes y cada uno intenta ejecutar sus tareas lo más rápidamente posible.
Esto provoca problemas de concurrencia. Por ejemplo,
- La CPU envía comandos a la GPU y escribe en memoria de la GPU los recursos necesarios para renderizar el frame N
- La GPU comienza a procesar los comandos y leer en memoria los recursos
- La CPU, que no espera a nadie, ¡comienza a escribir los recursos para el frame N+1! Pero la GPU aún está renderizando el frame N
Estos problemas de sincronización hay que resolverlos.
Es necesario elementos de sincronización entre CPU y GPU. Lo veremos.
Resumen
Con DirectX 12, hasta para los usos más básico, necesitamos:
- Configurar el pipeline.
- Crear colas para enviar comandos a la GPU.
- Gestionar los recursos y memoria de la GPU.
- Sincronizar CPU / GPU
En el siguiente tutorial crearemos las colas de comandos.
Queue
Para poder enviar tareas a la GPU necesitamos encolarle comandos. En este tutorial veremos como se hace.
Command Queue
En DX12 nos comunicamos con la tarjeta gráfica usando la interfaz ID3D12Device.
¿Qué podemos hacer con la tarjeta gráfica?
La tarjeta gráfica es un dispositivo masivamente paralelo que ejecuta una serie de comandos.
Un comando es una orden que puede ser: "procesa estos vértices", "borra la pantalla con este color", "copia esta textura a la memoria", etc.,
La tarjeta gráfica utiliza una cola de comandos. Tú, como programador, envías comandos a la cola y la GPU los irá procesando.
Si queremos que la GPU haga algo, necesitamos acceder a su cola de comandos.
Crear la Command Queue
Para crear una cola de comandos (Command Queue) procedemos del modo habitual en DirectX: rellenar una estructura y luego llamar a un método Create_XXXX con dicha estructura:
D3D12_COMMAND_QUEUE_DESC CommandQueueDesc{};
// Hay distintos tipos de colas como:
// D3D12_COMMAND_LIST_TYPE_COMPUTE
// para temas relacionados con compute shader
// pero nosotros queremos usar la cola gráfica:
CommandQueueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
// para temas de usar múltiples nodos GPU.
// para uso de una sola GPU se pone a 0
CommandQueueDesc.NodeMask = 0;
// La prioridad de la cola, normalmente NORMAL
CommandQueueDesc.Priority = D3D12_COMMAND_QUEUE_PRIORITY_NORMAL;
// Flags adicionales. En estos momentos solo hay dos:
// D3D12_COMMAND_LIST_TYPE_BUNDLE
// D3D12_COMMAND_QUEUE_FLAG_DISABLE_GPU_TIMEOUT
CommandQueueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
// Una vez rellenada la estructura, crear el CommandQueue
Device->CreateCommandQueue(&CommandQueueDesc, IID_PPV_ARGS(&CommandQueue));Command List
¿Ya podemos enviar comandos a la CommandQueue? No, los comandos no se envían "sueltos", si no que se envían empaquetados en listas de comandos.
Esto se hace principalmente por eficiencia. Enviar listas enteras de comandos es mucho más eficiente para el binomio CPU/GPU que tener que enviarlos de uno a uno.
ComPtr<ID3D12CommandList> CommandList;
// ... crear la command list
// Empezar a grabar comandos
CommandList->Reset(...);
// Y añadimos los comandos que queremos que la GPU ejecute a la lista.
// Los comandos se ejecutan de forma secuencial
CommandList->BorraLaPantalla(ConEsteColor);
// el método de verdad se llama ClearRenderTargetView, ya lo veremos
CommandList->ProcesaEstosVertices(BufferDeVertices); // 2º comando
CommandList->LaSalidaDelRenderEsEsta(TexturaSalida); // 3º comando
// ... grabar más comandos
// Hemos terminado de grabar todos los comandos en la lista
CommandList->Close();Nota importante: ¡No estamos enviando ningún comando a la cola! Simplemente estamos grabando los comandos en la lista.
Se usa Reset() para empezar a grabar, se llama a métodos de CommandList para indicar los comandos a grabar y terminamos la grabación con Close().
Para enviar la lista de comandos y que, efectivamente, se ejecuten, hay que hacer:
ComPtr<ID3D12CommandList> CommandList;
// ...
ID3D12CommandList* ppCommandLists[] = { CommandList.Get() };
CommandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);Nota como se pueden enviar varias listas de comandos en una sola llamada.
En el ejemplo la GPU ejecutaría en orden: borrar la pantalla, procesar los vértices, setear la salida a una textura, y el resto de comandos adicionales.
En CommandList se graban los comandos con Reset y Close, ¡pero no se ejecutan!.
Para que se ejecuten hay que enviarle la lista a la CommandQueue con ExecuteCommandList.
Command Allocator
¿Cómo creamos una CommandList? Los CommandList necesitan un espacio de memoria en la GPU dónde almacenar los comandos que se graben.
Este espacio de memoria está expuesto en la api en la clase ID3D12CommandAllocator.
Así que si queremos crear un CommandList antes debemos reservar espacio de memoria en la GPU para almacenar dicha lista. Para ello creamos previamente un command allocator:
ComPtr<ID3D12GraphicsCommandList> CommandAllocator;
Device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(&CommandAllocator));Y entonces creamos la CommandList:
ID3D12PipelineState* InitialState = nullptr; // ya veremos que es esto
Device->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_DIRECT, CommandAllocator.Get(), InitialState, IID_PPV_ARGS(&CommandList));Para crear una command list necesitamos su allocator y el estado inicial del pipeline. Veremos que es eso del estado del pipeline en posteriortes tutoriales.
Varias CommandList pueden estar asociadas a un único CommandAllocator. El requisito indispensable es que solo una command list puede estar grabando a la vez.
Hemos visto que para comenzar a grabar un command list hay que usar el método Reset(). ¡También hay que hacerlo en CommandAllocator!
ComPtr<ID3D12CommandAllocator> CommandAllocator;
Device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(&CommandAllocator));
ComPtr<ID3D12GraphicsCommandList> CommandList;
ID3D12PipelineState* InitialState = nullptr; // ya veremos que es esto
Device->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_DIRECT, CommandAllocator.Get(), InitialState, IID_PPV_ARGS(&CommandList));
// Empezar a grabar comandos
CommandAllocator->Reset(); // borrar comandos grabados
CommandList->Reset(&CommandAllocator.Get(), InitialState);
// y añadimos los comandos que queremos que la GPU ejecute a la lista
// los comandos se ejecutan de forma secuencial
CommandList->BorraLaPantalla(ConEsteColor);
// el método de verdad se llama ClearRenderTargetView, ya lo veremos
CommandList->ProcesaEstosVertices(BufferDeVertices); // 2º comando
CommandList->LaSalidaDelRenderEsEsta(TexturaSalida); // 3º comando
// ... grabar más comandos
// Hemos terminado de grabar todos los comandos en la lista
CommandList->Close();
// los comandos se han guardado en CommandAllocator
// ¡¡ no se han encolado para su ejecución !! simplemente se han grabado para su posterior ejecución
// en algún momento, en algún punto de la ejecución, se hará esto:
ID3D12CommandList* ppCommandLists[] = { CommandList.Get() };
CommandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
// y los comandos se encolarán en la cola de comandos para su ejecuciónCódigo final
Con todo esto el código final sería:
// DemoApp.h
class DemoApp
{
public:
DemoApp();
private:
ComPtr<IDXGIFactory4> Factory;
ComPtr<ID3D12Device> Device;
ComPtr<ID3D12CommandQueue> CommandQueue;
ComPtr<ID3D12CommandAllocator> CommandAllocator;
ComPtr<ID3D12GraphicsCommandList> CommandList;
void CreateDevice();
void CreateQueues();
};
````
````cpp
// DemoApp.cpp
DemoApp::DemoApp()
{
CreateDevice();
CreateQueues();
}
void DemoApp::CreateDevice() { ... }
void DemoApp::CreateQueues()
{
// CommandQueue
D3D12_COMMAND_QUEUE_DESC CommandQueueDesc{};
CommandQueueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
CommandQueueDesc.NodeMask = 0;
CommandQueueDesc.Priority = D3D12_COMMAND_QUEUE_PRIORITY_NORMAL;
CommandQueueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
Device->CreateCommandQueue(&CommandQueueDesc, IID_PPV_ARGS(&CommandQueue));
// Command Allocator
Device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(&CommandAllocator));
// Command List
ID3D12PipelineState* InitialState = nullptr;
Device->CreateCommandList(
0,
D3D12_COMMAND_LIST_TYPE_DIRECT,
CommandAllocator.Get(),
InitialState,
IID_PPV_ARGS(&CommandList)
);
// Por defecto cuando creas un CommandList está grabando
CommandList->Close();
}Sincronizacion CPU / GPU
Ya podemos enviar comandos a la GPU. Sin embargo, esto es solo una parte del puzzle.
Necesitamos poder copiar a la GPU los distintos recursos que necesita para trabajar: vértices, matrices, texturas, etc.,
También usamos recursos para que la GPU escriba su resultado final (el render) y podamos mostrarlo por pantalla. De hecho el render final es almacenado en una textura llamada render target.
Los vertex buffer, index buffer, render targets, depth map, texturas varias como albedo, roughness, normal maps, etc., todos ellos son recursos que se alojan en la memoria de la GPU.
Gestionar la memoria de la GPU es obligatorio incluso para los ejemplos/usos más simples de DX12.
El siguiente tutorial hablaremos de los recursos.
Sin embargo, el punto aquí es que la CPU escribe comandos, por ejemplo copia este recurso, devuélveme el render target para mostrarlo por pantalla, etc., y la GPU ejecuta los comandos.
¡Tanto la CPU como la GPU van a cada una a su ritmo!
¿Y qué problema puede ocasionar eso? Pues por ejemplo la CPU puede empezar a enviar datos a la GPU para preparar el frame número 15 cuando la GPU aún está calculando el frame número 14.
Te puedes hacer una idea de los enormes problemas de desincronización (sobre todo dolores de cabeza) que la CPU y GPU vayan cada a una a su ritmo sin puntos de sincronía.
Necesitamos algún modo de sincronizar la GPU y la CPU.
En concreto, sería ideal algún método que haga que la CPU "espere" a que la GPU haya terminado de procesar todos los comandos. Algo así como un "flush" para la cola de comandos que haga esperar a la CPU hasta que la GPU haya vaciado la cola.
Para este propósito necesitaremos un objeto de sincronización llamado Fence.
Fence
Un Fence es un objeto que permite sincronizar la CPU con la GPU.
¿Cómo funciona?
Es muy fácil. Un Fence almacena un entero de 64 bits.
La GPU puede setear el valor de dicho entero usando el comando Signal.
ComPtr<ID3D12Fence> Fence;
Device->CreateFence(
0, // valor inicial
D3D12_FENCE_FLAG_NONE,
IID_PPV_ARGS(&Fence)
);
// .. encolamos comandos con CommandQueue->ExecuteCommandList
const UINT64 SomeValue = 72;
CommandQueue->Signal(Fence.Get(), SomeValue);En este caso, encolamos el comando "setea el fence con el valor 72".
Por tanto, podemos concluir que Fence tendrá el valor 72 cuando haya completado todos los comandos previos a Signal.
La CPU puede esperar a un fence a que tenga un valor concreto.
Windows tiene una API para sincronización basada en eventos.
HANDLE FenceEvent;
FenceEvent = CreateEvent(nullptr, FALSE, FALSE, nullptr);Y podemos esperar a que ocurra un evento:
// la ejecución se para aquí hasta que ocurre el evento
WaitForSingleObject(FenceEvent, INFINITE);¿Cómo indicamos al objeto FenceEvent que el evento es, efectivamente, "el fence tiene el valor X"?
Usando el propio objeto Fence:
Fence->SetEventOnCompletion(SomeValue, FenceEvent);Todo el código junto:
HANDLE FenceEvent;
FenceEvent = CreateEvent(nullptr, FALSE, FALSE, nullptr);
// ...
Fence->SetEventOnCompletion(SomeValue, FenceEvent);
WaitForSingleObject(FenceEvent, INFINITE);Con todo esto, podemos implementar el método FlushAndWait que hemos comentado en el apartado anterior.
Dicho método hará que la CPU espere a que la GPU haya completado todos los comandos que tenga encolados.
Añade el siguiente código:
// DemoApp.h
class DemoApp
{
// ...
private:
// ...
/* Fences */
ComPtr<ID3D12Fence> Fence;
HANDLE FenceEvent;
UINT64 FenceValue;
void CreateFence();
void FlushAndWait();
// ...
};
// DemoApp.cpp
DemoApp::DemoApp()
{
// ...
CreateFence();
}
void DemoApp::CreateFence()
{
FenceValue = 0;
Device->CreateFence(FenceValue, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&Fence));
FenceEvent = CreateEvent(nullptr, FALSE, FALSE, nullptr);
}
void DemoApp::FlushAndWait()
{
// encolamos a la GPU el comando:
// "setea el valor de fence con este valor"
const UINT64 FenceValueToSignal = FenceValue;
CommandQueue->Signal(Fence.Get(), FenceValueToSignal);
// incrementamos FenceValue
// para la siguiente vez que se llame
++FenceValue;
// si el valor de fence aún no es el valor que le dijimos
// a la GPU que marcase, significa que aún no ha llegado
// a ese comando. Esperamos.
if (Fence->GetCompletedValue() < FenceValueToSignal)
{
Fence->SetEventOnCompletion(FenceValueToSignal, FenceEvent);
WaitForSingleObject(FenceEvent, INFINITE);
}
}Todo en práctica
Un uso típico sería algo así:
/******
Etapa inicial: copiar a la memoria de la GPU los recursos
*******/
// iniciamos la grabación
CommandAllocator->Reset();
CommandList->Reset(&CommandAllocator.Get(), InitialState);
// Grabar comandos comunmente iniciales
// como copiar recursos: vertex buffer, texturas, etc.,
CommandList->Close();
// Ejecutar los comandos
ID3D12CommandList* ppCommandLists[] = { CommandList.Get() };
CommandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
FlushAndWait(); // asegurarnos que todos los recursos iniciales estan copiados porque la GPU ha vaciado su cola
/******
Para cada frame
*******/
while(true)
{
// Iniciamos la grabación
CommandAllocator->Reset();
CommandList->Reset(&CommandAllocator.Get(), InitialState);
// Grabar comandos típicos del render
// como copiar los vértices, indicar cuál es el render target, etc.,
// indicar con sucesivas llamadas a CommandList->DrawXXXXXX qué pintar
CommandList->Close();
// Ejecutar la lista de comandos
ID3D12CommandList* ppCommandLists[] = { CommandList.Get() };
CommandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
// Esperar a que la GPU termine de procesar este frame antes de pasar al siguiente. Punto de sincronización entre CPU/GPU
FlushAndWait();
}Siguientes pasos
Ya podemos enviar comandos a la GPU. Es hora de hablar de los recursos.
Resources
Necesitamos gestionar la memoria de la GPU para poder copiar recursos desde la CPU.
Ejemplos de recursos son los vértices que queremos que pinte, las texturas, incluso la propia salida de la GPU: la escena renderizada.
Memoria en la GPU
Al final del proceso de la GPU tenemos un resultado, un render de la escena. Este render final es almacenado en una textura. A esta textura se le denomina RenderTarget.
Así que si queremos que la GPU escriba algo debemos reservar espacio en la memoria de la GPU para este render target.
También queremos pasarle una lista de vértices. Estos vértices se deben copiar a la GPU. Así que tenemos que reservar espacio en la memoria de la GPU para el vertex buffer.
Probablemente queramos usar texturas, como mapa de normales, difuso, etc., para cada uno de ellos habrá que reservar espacio en la GPU.
En definitiva, debemos saber como reservar espacio de memoria en la GPU.
Los render target, vertex buffer, texturas, etc., que son almacenados en la memoria de la GPU se llaman recursos. Y al espacio de memoria dónde se almacena resource heap.
Recursos
Un recurso a ojos de la GPU no es más que el espacio de memoria asignado a una textura.
Cuando pensamos en texturas se nos viene a la cabeza los mapas de color como albedo, difuso, etc., pero lo cierto es que una textura puede contener mucho más.
Por ejemplo, un vertex buffer, que es un array de vértices, lo puedes ver como una textura 1D. Al igual que un index buffer.
Un render target es una textura 2D, también lo es un depth map, shadow map, normal map y cuando hablamos de "texturas" en general.
Podemos ampliar la definición de recurso anterior y decir que un recurso es un espacio de memoria de una textura multidimensional, capaz de almacenar texturas 1D, 2D ó 3D.
Gracias a esta versatibilidad podemos almacenar cualquier recurso (desde un array = textura 1D, pasando por mapas de normales = textura 2D, o volúmenes = textura 3D por poner algunos ejemplos).
Los recursos en DirectX12 se representan con la clase ID3D12Resource. Y, como es habitual, para conseguir un recurso (esto es, una ID3D12Resource) necesitamos rellenar una estructura que describa el recurso.
Hemos dicho que los recursos son el espacio de memoria asignado a una textura. Por lo que no es sorprendente que la estructura que hay que rellenar para describir el recurso habla de conceptos propios de una textura (como el ancho o el alto):
D3D12_RESOURCE_DESC ResourceDesc{};
ResourceDesc.Dimension = ...;
/*
D3D12_RESOURCE_DIMENSION_BUFFER,
D3D12_RESOURCE_DIMENSION_TEXTURE2D,
D3D12_RESOURCE_DIMENSION_TEXTURE3D
*/
ResourceDesc.Width = ...; // primera dimension, el ancho
ResourceDesc.Height = ...; // segunda dimension, el alto
ResourceDesc.DepthOrArraySize = ...; // tercera dimension, la profundidad
ResourceDesc.Alignment = ...
/*
D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT == alienar en 64KB
D3D12_DEFAULT_MSAA_RESOURCE_PLACEMENT_ALIGNMENT == alienar en 4MB para temas de MSAA si usas MSAA
*/
ResourceDesc.Layout = ...;
/*
D3D12_TEXTURE_LAYOUT_ROW_MAJOR para indicar que los datos
deben almacenarse de manera contigua
D3D12_TEXTURE_LAYOUT_UNKOWN para indicar que la GPU se
encargue de almacenar el recurso del modo que mejor crea conveniente
*/
// Sin flags.
ResourceDesc.Flags = ...;
/* Valores interesantes:
D3D12_RESOURCE_FLAG_NONE
D3D12_RESOURCE_FLAG_ALLOW_RENDER_TARGET
D3D12_RESOURCE_FLAG_ALLOW_DEPTH_STENCIL
Son flags que indican a DirectX el propósito del recurso
para así optimizarlo. Además como medida de seguridad
si usas como render target un recurso que no esté marcado
con el flag D3D12_RESOURCE_FLAG_ALLOW_RENDER_TARGET dará error
al igual que con DepthStencil.
*/
ResourceDesc.MipLevels = 1;
/* Número de MIP de esta textura.
En general lo tendrás en 1 salvo que uses mipmap.
https://en.wikipedia.org/wiki/Mipmap
*/
// y otros campos como Format, etc.,Con esta estructura llamaremos a una función para crear un recurso (enseguida la veremos). Esta función nos devolverá un ID3D12Resource.
Veamos algunos ejemplos de como declarar recursos.
Declarar un recurso para una textura:
D3D12_RESOURCE_DESC ResourceDesc{};
ResourceDesc.Width = TextureWidth;
ResourceDesc.Height = TextureHeight;
ResourceDesc.DepthOrArraySize = 1;
ResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D;
ResourceDesc.Alignment = D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT;
ResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKOWN;
/* que la GPU determine cuál es la mejor disposición
para almacenar en memoria el recurso */
ResourceDesc.Flags = D3D12_RESOURCE_FLAG_NONE;
ResourceDesc.MipLevels = 1;
ResourceDesc.SampleDesc.Count = 1;
ResourceDesc.SampleDesc.Quality = 0;
ResourceDesc.Format = TextureFormat; // por ejemplo, DXGI_FORMAT_R8G8B8A8_UNORM para almacenar el colorDeclarar una textura para el depth map:
D3D12_RESOURCE_DESC ResourceDesc{};
ResourceDesc.Width = ViewportWidth;
ResourceDesc.Height = ViewportHeight;
ResourceDesc.DepthOrArraySize = 1;
ResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D;
ResourceDesc.Alignment = D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT;
ResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKOWN;
/* que la GPU determine cuál es la mejor disposición
para almacenar en memoria el recurso */
ResourceDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_DEPTH_STENCIL;
ResourceDesc.MipLevels = 1;
ResourceDesc.SampleDesc.Count = 1;
ResourceDesc.SampleDesc.Quality = 0;
ResourceDesc.Format = DXGI_FORMAT_D24_UNORM_S8_UINT;
// 24 bits para el depth y 8 bits para el stencil
// otros valor podría ser:
// DXGI_FORMAT_D32_FLOAT -> solo depthDeclarar un recurso para un buffer, como un Vertex Buffer ó Index Buffer:
struct MyVertex {
XMFLOAT3 Position;
XMFLOAT3 Normal;
XMFLOAT2 UV;
// ... otros ...
};
MyVertex[] Vertices = { .... };
D3D12_RESOURCE_DESC ResourceDesc{};
ResourceDesc.Width = sizeof(Vertices);
ResourceDesc.Height = 1;
ResourceDesc.DepthOrArraySize = 1;
ResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER;
ResourceDesc.Alignment = D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT;
ResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR;
// dado que es un buffer, no queremos que la GPU almacene
// de cualquier modo la textura en memoria. Con ROW_MAJOR
// indicamos que la disposición debe contigua en memoria.
ResourceDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_NONE;
ResourceDesc.MipLevels = 1;
ResourceDesc.SampleDesc.Count = 1;
ResourceDesc.SampleDesc.Quality = 0;
ResourceDesc.Format = DXGI_FORMAT_UNKNOWN;
/* en este caso no estamos obligados a tener un formato,
así que lo seteamos a desconocido para que la GPU
lo almacene en el formato que mejor le convenga */Ya sabemos como declarar recursos. Ahora toca almacenarlo en memoria.
Resource Heap
Todos los recursos deben estar alojados en memoria. Para ello necesitamos reservar un espacio de memoria para alojarlo.
Al final de este tutorial veremos el código concreto pero antes necesitamos crear la intuición de cómo funciona la gestión de memoria así que omitiremos algunos parámetros en las llamadas con objeto de centrarnos en lo importante.

Lo primero es reservar espacio de memoria. A este espacio se denomina Resource Heap:
D3D12_HEAP_DESC HeapDesc{};
HeapDesc.SizeInBytes = /* un entero indicando el tamaño total a reservar */
HeapDesc.Type = /* tipo de heap, lo veremos más adelante */
Device->CreateHeap(&HeapDesc, IID_PPV_ARGS(&ResourceHeap));Con el código anterior reservamos un espacio de memoria (resource heap):
Y posteriormente colocamos el recurso en el heap:
ComPtr<ID3D12Resource> Resource;
D3D12_RESOURCE_DESC ResourceDesc{};
// ... la estructura que hemos visto en el apartado anterior
Device->CreatePlacedResource(
ResourceHeap.Get(),
..., // enseguida veremos que hay aquí
&ResourceDesc,
..., // enseguida veremos que hay aquí
IID_PPV_ARGS(&Resource)
);La llamada anterior coloca el recurso en el heap:

Podemos usar el mismo heap para alojar más de un recurso, con llamadas sucesivas a CreatePlacedResource:

Sin embargo, es muy habitual reservar el espacio de memoria justo para que quepa un solo recurso. Podemos usar el método CreateCommittedResource para reservar la memoria justa para el recurso (CreateHeap) y colocar el recurso (CreatePlaceableResource) en una sola llamada:
ComPtr<ID3D12Resource> Resource;
D3D12_RESOURCE_DESC ResourceDesc{};
// ... tal y como hicimos en el apartado anterior ...
D3D12_HEAP_PROPERTIES HeapProps{};
// HeapDesc.SizeInBytes no hace falta indicar el tamaño del heap,
// el método CreateCommittedResource lo deducirá de ResourceDesc
HeapProps.Type = /* tipo de heap */;
Device->CreateCommittedResource(
&HeapProps,
...,
&ResourceDesc,
...,
...,
IID_PPV_ARGS(&Resource)
);El código anterior reserva espacio y coloca el recurso, basicamente es la llamada CreateHeap y CreatePlaceableResource en una sola. Perfecto para recursos relativamente grandes.

Para recursos pequeños quizás sería interesante hacer nosotros explícitamente las llamadas a CreateHeap y CreatePlaceableResource para reutilizar lo máximo posible el heap.
Para completar el código anterior con el resto de parámetros que hemos dejado marcado con "..." necesitamos entender un par de conceptos más.
Resource Barrier
Uno de los problemas que hay que afrontar con DirectX 12 es la concurrencia (paralelismo).
Considera por ejemplo un render target, se trata de una textura almacenada en la memoria de la GPU, por definición es un recurso.
La GPU escribirá en el render target el resultado de renderizar la escena. También tendrá que leer del render target para mostrar por pantalla.
Escribir y leer. No hay problema si se hace secuencial, ¡pero la GPU es multicore y paralela! Podría ocurrir que se escribiera mientras se leyese. Cosas malas ocurrirían.
Del mismo modo podemos razonar con otros recursos. Por ejemplo para un shadow map, enviaremos comandos a la GPU para que calcule el shadow map en una textura. Posteriormente leeremos dicha textura para saber dónde hay sombras. Mismo problema, al ser la GPU paralela puede ocurrir escritura y lectura a la vez del mismo recurso.
Para evitar esta problemática y sincronizar el uso de los recursos dentro de la GPU, las GPU modernas permiten añadir barreras.
Una barrera no es más que indicar el "uso" que se le va a dar al recurso durante un tiempo determinado.
A este "uso" se le denomina estado.
Por ejemplo, estado de solo lectura. De manera que si algún comando intenta escribir saltará una excepción.
Esto no es algo opcional, los recursos siempre están en algún estado. Y dependiendo del estado tienes permitido efectuar unas operaciones u otras con ellos.
Podemos cambiar el estado del recurso usando comandos.
Pues bien, uno de los argumentos de la función CreateCommittedResource y CreatePlacedResource es el estado inicial del recurso.
ComPtr<ID3D12Resource> Resource;
// ...
Device->CreateCommittedResource(
&HeapProps,
...,
&ResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, // estado inicial
...,
IID_PPV_ARGS(&Resource)
);No solo existen el estado de leíble y escribible. Existen multitud de estados para indicar a la GPU el propósito concreto que le vamos a dar al recurso. De este modo la GPU puede optimizar el recurso.
Otros estados pueden ser:
- D3D12_RESOURCE_STATE_GENERIC_READ – este recurso es leíble
- D3D12_RESOURCE_STATE_COPY_DEST – vamos a copiar algo al recurso
- D3D12_RESOURCE_STATE_PRESENT – este recurso está listo para presentarlo por pantalla
- D3D12_RESOURCE_STATE_RENDER_TARGET – vamos a escribir en este recurso que además es un render target
- D3D12_RESOURCE_STATE_DEPTH_WRITE – vamos a escribir en este recurso que además es un depth map
- Y más estados
Puedes ver los estados como representaciones abstractas del uso que se le va a dar al recurso.
A la hora de la verdad quizás la GPU trate igual a un recurso en los estados D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_RENDER_TARGET y D3D12_RESOURCE_STATE_DEPTH_WRITE, porque a esa GPU concreta de la marca que sea solo le interesa saber que el recurso es escribible. Las demás consideraciones les resulta irrelevantes. Otras GPU quizás diferencien en si es un recurso para depth o no para optimizar. Dependerá de la implementación concreta del driver y del fabricante.
En lo que a nosotros nos concierne usamos el estado para indicar el uso y ya que la GPU lo gestione del mejor modo.
Muchos de estos estados son "superestados". Por ejemplo el estado D3D12_RESOURCE_STATE_GENERIC_READ es la combinación de:
- D3D12_RESOURCE_STATE_VERTEX_AND_CONSTANT_BUFFER
- D3D12_RESOURCE_STATE_DEPTH_READ
- D3D12_RESOURCE_STATE_COPY_SOURCE
- ...
Es mejor usar el estado más concreto posible. Es decir, si queremos leer de un recurso que representa un depth map, mejor usar D3D12_RESOURCE_STATE_DEPTH_READ que D3D12_RESOURCE_STATE_GENERIC_READ. De este modo aprovechamos todas las optimizaciones internas que puede ofrecer la GPU.
Aquí tienes una lista de los estados.
¿Y si queremos cambiar el estado de un recurso?
Usando comandos:
D3D12_RESOURCE_BARRIER ResourceBarrier{};
ResourceBarrier.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSITION;
ResourceBarrier.Flags = D3D12_RESOURCE_BARRIER_FLAG_NONE;
ResourceBarrier.Transition.pResource = /* el recurso ID3D12Resource */;
ResourceBarrier.Transition.StateBefore = D3D12_RESOURCE_STATE_RENDER_TARGET; // el estado previo
ResourceBarrier.Transition.StateAfter = D3D12_RESOURCE_STATE_PRESENT; // el estado posterior
ResourceBarrier.Transition.Subresource = D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES;
CommandList->ResourceBarrier(
1, // cuantas resource barriers
&ResourceBarrier // array con las resources barriers
);Tipos de heap
Tomemos el código anterior:
D3D12_RESOURCE_DESC ResourceDesc{};
D3D12_HEAP_PROPERTIES HeapProps{};
HeapProps.Type = /* tipo de heap */;
Device->CreateCommittedResource(
&HeapProps,
...,
&ResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, // estado inicial
...,
IID_PPV_ARGS(&Resource)
);La propiedad HeapProps.Type indica el tipo de Heap.
Recuerda que un heap es un trozo de memoria en la GPU que hemos reservado para alojar uno o más recursos.
Si un heap es un trozo de memoria de la GPU, ¿cómo puede acceder la CPU a ella? Por ejemplo, para subir los vértices o las texturas. Respuesta: No puede.
¿Entonces? ¿Cómo copiamos los datos de la memoria de la CPU a la memoria de la GPU?
La memoria de la GPU tiene un espacio reservado dónde la CPU puede escribir. A este espacio se dice que es de tipo UPLOAD.
En los heap de tipo upload la CPU puede escribir y la GPU puede leer. ¡Es el único espacio de memoria dónde puede escribir la CPU!
D3D12_HEAP_PROPERTIES HeapProps{};
HeapProps.Type = D3D12_HEAP_TYPE_UPLOAD;El resto de memoria es de tipo DEFAULT y la CPU no tiene acceso. La GPU puede escribir y leer a placer en DEFAULT.
Así que, por fin, nos queda el siguiente código para crear y alojar un recurso en memoria:
ComPtr<ID3D12Resource> Resource;
D3D12_RESOURCE_DESC ResourceDesc{};
// ... tal y como hicimos en el apartado anterior ...
D3D12_HEAP_PROPERTIES HeapProps{};
HeapProps.Type = D3D12_HEAP_TYPE_UPLOAD;
Device->CreateCommittedResource(
&HeapProps,
D3D12_HEAP_FLAG_NONE, // flags indicando si este heap permite que se almacenen exclusivamente buffers, o solo texturas, etc., lo normal es dejarlo en none
&ResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, // estado inicial
nullptr, // ClearValue para inicializar el recurso con un valor inicial
IID_PPV_ARGS(&Resource)
);Ya tenemos el recurso, y en un estado inicial listo para poder ser leído por la GPU. Además hemos alojado el recurso en un heap de tipo Upload así que podemos copiar datos desde la CPU.
¿Cómo podemos copiar si el estado es de leer?
El estado se refiere al estado desde el punto de vista de la GPU. La CPU puede leer o escribir en función del tipo de heap dónde esté alojado el recurso. La GPU en función del estado en el que se encuentre el recurso.
En el ejemplo, el heap es de tipo UPLOAD así que la CPU puede escribir. En el ejemplo el recurso está en estado READ así que la GPU puede leerlo sin problemas.
Copiar de la CPU a la GPU
¿Cómo copiamos datos desde la CPU?
Haciendo uso del método Map. Este método tiene como argumento de salida un puntero para poder escribir en él:
// Copiar de la CPU a la GPU
UINT* pData;
/*
Rango de lectura.
No queremos leer nada, el puntero no será leíble
*/
D3D12_RANGE ReadRange;
ReadRange.Begin = 0;
ReadRange.End = 0;
// conseguir un puntero pData válido para escribir en el recurso
Resource->Map(
0, // indice del subrecurso (*)
&ReadRange,
&pData
);
memcpy(pData, Vertices, sizeof(Vertices));
// invalidar el puntero y flushear la cache de la GPU
Resource->Unmap(
0,
nullptr // rando de valores escritos, nullptr para indicar que es todo el rango
);[*] El índice del subrecurso es porque una textura puede contener, a su vez, subrecursos. Por ejemplo, para un mip level > 1 tenemos varios subrecursos.
Recuerda que el heap dónde está alojado el recurso debe ser de tipo UPLOAD si no la CPU no tiene permiso para escribir.
Heap de tipo Default
Si el único modo de pasar datos de la CPU a la GPU es con un heap de tipo UPLOAD, ¿para qué queremos los de tipo DEFAULT?
Como sin duda estarás pensado, el heap de tipo DEFAULT es muchísimo más eficiente que el de tipo UPLOAD. Los de tipo DEFAULT son exclusivos para la GPU y allí es dónde la GPU vuela.
Para los recursos que no cambian de frame a frame, por ejemplo los vertex buffer o texturas de materiales (mapa de normales, etc.,), se trata de un lugar fantástico dónde alojarlos.
Ok. Copiarlos desde la CPU tenemos que copiarlos forzosamente a un heap de tipo UPLOAD, pero luego nada nos impide que la propia GPU (que puede leer en UPLOAD y escribir en DEFAULT) copie el recurso de UPLOAD a DEFAULT. Para ello, como no, usamos un comando.
Vamos paso a paso.
Primero. Recurso en UPLOAD, tal y como hemos visto:
D3D12_RESOURCE_DESC ResourceDesc{};
// ... descripción del recurso tal y como hicimos en el apartado anterior ...
ComPtr<ID3D12Resource> Resource_Upload;
D3D12_HEAP_PROPERTIES HeapProps_Upload{};
HeapProps_Upload.Type = D3D12_HEAP_TYPE_UPLOAD;
Device->CreateCommittedResource(
&HeapProps_Upload,
D3D12_HEAP_FLAG_NONE,
&ResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(&Resource_Upload)
);Segundo. Recurso en default.
ComPtr<ID3D12Resource> Resource_Default;
D3D12_HEAP_PROPERTIES HeapProps_Default{};
HeapProps_Default.Type = D3D12_HEAP_TYPE_DEFAULT;
Device->CreateCommittedResource(
&HeapProps_Default,
D3D12_HEAP_FLAG_NONE,
&ResourceDesc,
D3D12_RESOURCE_STATE_COPY_DEST, // recurso en estado para copiar
nullptr,
IID_PPV_ARGS(&Resource_Default)
);Tercero. Ahora los dos recursos están alojados en memoria, en heaps de distinto tipo, pero están vacíos. Copiamos los datos desde la CPU:
// solo podemos escribir datos a Resouce_Upload
UINT* pData;
D3D12_RANGE ReadRange;
ReadRange.Begin = 0;
ReadRange.End = 0;
Resource_Upload->Map(0, &ReadRange, &pData);
memcpy(pData, Vertices, sizeof(Vertices));
Resource->Unmap(0, nullptr);Cuarto. Nosotros, la CPU, no podemos copiar el recurso a default. Se lo indicamos a la GPU mediante un comando:
CommandList->CopyResource(Resource_Upload.Get(), Resource_Default.Get());Quinto. Una vez copiado el recurso. Le cambiamos el estado para que pueda ser leído en la GPU:
D3D12_RESOURCE_BARRIER RB_FromCopyDstToRead{};
RB_FromCopyDstToRead.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSITION;
RB_FromCopyDstToRead.Flags = D3D12_RESOURCE_BARRIER_FLAG_NONE;
RB_FromCopyDstToRead.Transition.StateBefore = D3D12_RESOURCE_STATE_COPY_DEST;
RB_FromCopyDstToRead.Transition.StateAfter = D3D12_RESOURCE_STATE_GENERIC_READ;
RB_FromCopyDstToRead.Transition.Subresource = D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES;
RB_FromCopyDstToRead.Transition.pResource = Resource_Default.Get();
CommandList->ResourceBarrier(1, &RB_FromCopyDstToRead);Y a partir de aquí cada vez que necesitemos el recurso en algún comando, usaremos la referencia Resource_Default ya que está alojado en default, mucho más eficiente.
Clases para recursos
Vamos a crear una nueva clase en nuestro proyecto llamada GPUMem. Esta clase tendrá un conjunto de métodos estáticos que nos servirá para gestionar los recursos.
Básicamente es copiar el código que ya hemos visto anteriormente:
// GPUMem.h
#pragma once
#include <wrl.h>
using namespace Microsoft::WRL;
#include <d3d12.h>
class GPUMem
{
public:
static ComPtr<ID3D12Resource> Buffer(ID3D12Device* Device, SIZE_T SizeInBytes, D3D12_HEAP_TYPE HeapType);
static void ResourceBarrier(ID3D12GraphicsCommandList* CommandList, ID3D12Resource* Resource, D3D12_RESOURCE_STATES FromState, D3D12_RESOURCE_STATES ToState);
};// GPUMem.cpp
#include "GPUMem.h"
ComPtr<ID3D12Resource> GPUMem::Buffer(
ID3D12Device* Device,
SIZE_T SizeInBytes,
D3D12_HEAP_TYPE HeapType = D3D12_HEAP_TYPE_UPLOAD
)
{
ComPtr<ID3D12Resource> Resource;
D3D12_RESOURCE_DESC ResourceDesc{};
ResourceDesc.Width = SizeInBytes;
ResourceDesc.Height = 1;
ResourceDesc.DepthOrArraySize = 1;
ResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER;
ResourceDesc.Alignment = D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT;
ResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR;
ResourceDesc.Flags = D3D12_RESOURCE_FLAG_NONE;
ResourceDesc.MipLevels = 1;
ResourceDesc.SampleDesc.Count = 1;
ResourceDesc.SampleDesc.Quality = 0;
ResourceDesc.Format = DXGI_FORMAT_UNKNOWN;
D3D12_HEAP_PROPERTIES HeapProps{};
HeapProps.Type = HeapType;
Device->CreateCommittedResource(
&HeapProps,
D3D12_HEAP_FLAG_NONE,
&ResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(&Resource)
);
return Resource;
}
void GPUMem::ResourceBarrier(
ID3D12GraphicsCommandList* CommandList,
ID3D12Resource* Resource,
D3D12_RESOURCE_STATES FromState,
D3D12_RESOURCE_STATES ToState
)
{
D3D12_RESOURCE_BARRIER ResourceBarrierDesc{};
ResourceBarrierDesc.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSITION;
ResourceBarrierDesc.Flags = D3D12_RESOURCE_BARRIER_FLAG_NONE;
ResourceBarrierDesc.Transition.pResource = Resource;
ResourceBarrierDesc.Transition.StateBefore = FromState; // el estado previo
ResourceBarrierDesc.Transition.StateAfter = ToState; // el estado posterior
ResourceBarrierDesc.Transition.Subresource = D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES;
CommandList->ResourceBarrier(
1, // cuantas resource barriers
&ResourceBarrierDesc // array con las resources barriers
);
}Siguientes pasos
En el siguiente tutorial usaremos los recursos.
Descriptors
Para poder usar los recursos almacenados en la memoria de la GPU necesitamos descriptores. En este tutorial veremos que son y como crearlos.
¿Qué es un descriptor?
De los tutoriales anteriores hemos conseguido reservar espacio en memoria de la GPU y copiar datos.
Sin embargo existe un problema. Todos los cálculos se hacen con los registros de la GPU. Obviamente no puedes almacenar una textura o una matrix de 4x4 floats en un registro de 128 bits.
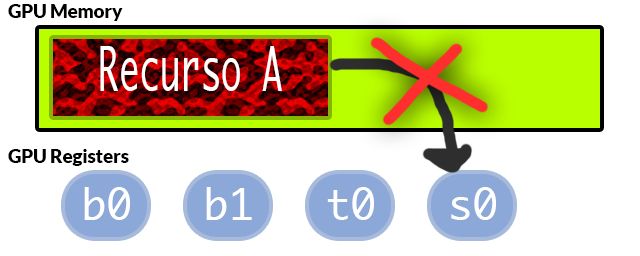
¿Cómo lo hacemos?
La idea es usar un descriptor. Un descriptor es una pequeña estructura que almacena la dirección dónde está alojado el recurso y su tamaño.
Este descriptor es el que usará el shader para cargar en alguno de sus registros.
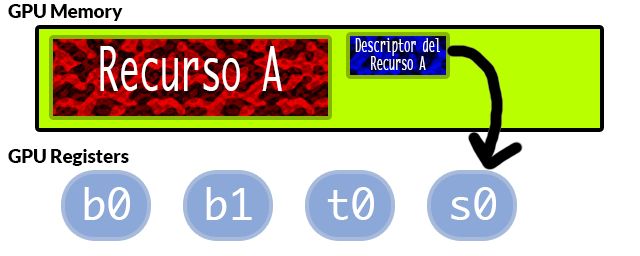
El panorama queda así, tenemos una serie de recursos:
ComPtr<ID3D12Resource> VertexBuffer;
ComPtr<ID3D12Resource> IndexBuffer;
ComPtr<ID3D12Resource> ContantBuffer;
ComPtr<ID3D12Resource> RenderTarget;Que para poder ser usados por la GPU debemos crear descriptores para cada uno:
// descriptor para vertex buffer
D3D12_VERTEX_BUFFER_VIEW VertexBufferView;
// descriptor para index buffer
D3D12_INDEX_BUFFER_VIEW VertexBufferView;
// descriptor para constant buffer
D3D12_CPU_DESCRIPTOR_HANDLE ConstantBufferView;
// descriptor para render target
D3D12_CPU_DESCRIPTOR_HANDLE RenderTargetView;Aquí view es sinónimo de descriptor.
Los descriptores, a su vez, están alojados en memoria de la GPU. La GPU puede cargar estos descriptores en sus registros.
Veamos en detalles algunos descriptores.
Descriptor para Vertex Buffer
Vamos a crear un descriptor para un recurso vertex buffer.
Empezamos con el recurso. De anteriores tutoriales sabemos como crear un Vertex Buffer.
FVertex TriangleVertices[] = {
...
};
ComPtr<ID3D12Resource> VertexBuffer;
// Alojado en memoria de la GPU y hemos copiado
// el array TriangleVertices en VertexBuffer
// como hemos visto en tutoriales anteriores
// Vamos a crear un descriptor para que pueda usarlo la GPU
D3D12_VERTEX_BUFFER_VIEW VertexBufferView;
// un descriptor no es más que una dirección en memoria y el tamaño
VertexBufferView.BufferLocation = VertexBuffer->GetGPUVirtualAddress();
VertexBufferView.SizeInBytes = sizeof(TriangleVertices);
VertexBufferView.StrideInBytes = sizeof(FVertex);¿Cómo usamos este descriptor?
Lo podemos usar como entrada de la etapa Input Assembler del pipeline:
CommandList->IASetVertexBuffers(
0, /* input slot, usually 0 */
1, /* number of vertex buffers descriptors in the array */
&VertexBufferView
);Descriptor para Index Buffer
Para crear un descriptor de un recurso Index Buffer:
DWORD Indices[] = {
0, 1, 2, // first triangle
0, 3, 1 // second triangle
};
ComPtr<ID3D12Resource> IndexBuffer;
// alojar memoria en la GPU para el recurso IndexBuffer
// y copiarle los datos de Indices, tal y como hemos visto
// en anteriores tutoriales
D3D12_INDEX_BUFFER_VIEW IndexBufferView;
IndexBufferView.BufferLocation = IndexBuffer->GetGPUVirtualAddress();
IndexBufferView.Format = DXGI_FORMAT_R32_UINT; // unsigned int 32 bits
IndexBufferView.SizeInBytes = sizeof(Indices);¿Cómo usamos este descriptor?
Lo usamos para indicar la entrada de la etapa Input Assembler del pipeline:
CommandList->IASetVertexBuffers(0, 1, &VertexBufferView);
CommandList->IASetIndexBuffer(&IndexBufferView); Descriptor Heap
¿Recuerdas lo que dijimos anteriormente?
"Los descriptores, a su vez, están alojados en memoria de la GPU. La GPU puede cargar estos descriptores en sus registros."
Sin embargo, no hemos alojado en memoria de la GPU ni VertexBufferView ni IndexBufferView.
Los descriptores para Vertex Buffer e Index Buffer son especiales tanto en cuanto se los pasamos directamente al pipeline con:
CommandList->IASetVertexBuffers(0, 1, &VertexBufferView);
CommandList->IASetIndexBuffer(&IndexBufferView); Estos comandos ya se ocupan de alojar los descriptores en memoria de la GPU y cargarlos en los registros correspondientes.
El resto de descriptores sí hay que alojarlos en memoria de la GPU.
Estos descriptores son del tipo:
D3D12_CPU_DESCRIPTOR_HANDLE ConstantBuffer, RenderTarget, ...;El espacio de memoria dónde se alojan los descriptores se llama descriptor heap. Puedes ver un descriptor heap como un array de descriptores.
La clase que representa un descriptor heap es ID3D12DescriptorHeap.
Para crear un descriptor heap:
D3D12_DESCRIPTOR_HEAP_DESC DescriptorHeapDesc{};
DescriptorHeapDesc.NumDescriptors = ...;
/* numero de descriptores que va a alojar, podrias pensar en esta propiedad como tamaño del array */;
DescriptorHeapDesc.Type = ...;
/* El tipo de descriptor que va a alojar
D3D12_DESCRIPTOR_HEAP_TYPE_RTV <- para descriptores render target
D3D12_DESCRIPTOR_HEAP_TYPE_DSV <- para descriptores depth stencil
D3D12_DESCRIPTOR_HEAP_TYPE_SAMPLER <- para descriptores sampler de texturas
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV <- para descriptores constantbuffer, shader view y unordered access
*/
DescriptorHeapDesc.Flags = ...;
/*
D3D12_DESCRIPTOR_HEAP_FLAG_NONE <- los descriptores alojados en este heap no serán visibles a las etapas programables (shaders)
D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE <- los descriptores alojados en este heap serán visibles a las etapas programables (shaders)
*/
DescriptorHeapDesc.NodeMask = 0;
ComPtr<ID3D12DescriptorHeap> DescriptorHeap;
Device->CreateDescriptorHeap(&DescriptorHeapDesc, IID_PPV_ARGS(&DescriptorHeap));Veamos algunos ejemplos para clarificarlo:
Descriptor para Render Target
Un render target es la textura que escribe la etapa Output Merge como resultado de ejecutar el pipeline.
Del mismo modo que hemos indicado previamente las entradas para Input Assembler con:
CommandList->IASetVertexBuffers(0, 1, &VertexBufferView);
CommandList->IASetIndexBuffer(&IndexBufferView); Debemos indicar la salida de Output Merger:
D3D12_CPU_DESCRIPTOR_HANDLE RenderTargetView = ...;
D3D12_CPU_DESCRIPTOR_HANDLE DepthStencilView = ...;
CommandList->OMSetRenderTargets(
1, // número de render targets
&RenderTargetView,
FALSE, // RTsSingleHandleToDescriptorRange
&DepthStencilView
);Los descriptores deben estar alojados en un heap:
ComPtr<ID3D12Resource> RenderTargets[4];
// Crear recursos render targets. En siguientes tutoriales veremos
// como hacerlo de manera efectiva.
ComPtr<ID3D12DescriptorHeap> RenderTargetViewHeap;
D3D12_DESCRIPTOR_HEAP_DESC RenderTargetViewHeapDesc{};
RenderTargetViewHeapDesc.NumDescriptors = kFrameCount;
RenderTargetViewHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV;
RenderTargetViewHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
RenderTargetViewHeapDesc.NodeMask = 0;
Device->CreateDescriptorHeap(&RenderTargetViewHeapDesc, IID_PPV_ARGS(&RenderTargetViewHeap));Ya tenemos el descriptor heap que tiene almacenado kFrameCount descriptores.
Puedes acceder al primer descriptor alojado en el descriptor heap usando el método:
D3D12_CPU_DESCRIPTOR_HANDLE DescriptorView = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();Si quieres el siguiente descriptor debes incrementar el puntero:
D3D12_CPU_DESCRIPTOR_HANDLE DescriptorView = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();
UINT HeapIncrementSize = Device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
DescriptorView.ptr += HeapIncrementSize;
// DescriptorView es ahora el segundo descriptor alojado en el heapPero estos descriptores aún no están asociados a ningún recurso.
Para ello se usa el método CreateRenderTargetView:
ComPtr<ID3D12Resource> RenderTargets[4];
D3D12_CPU_DESCRIPTOR_HANDLE DescriptorView = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();
// modificar DescriptorView.ptr para que apunte al descriptor deseado
Device->CreateRenderTargetView(
RenderTargets[FrameIndex].Get(),
nullptr,
DescriptorView
);Este sería un código bastante típico para asociar los descriptores a los recursos.
ComPtr<ID3D12Resource> RenderTargets[4];
ComPtr<ID3D12DescriptorHeap> RenderTargetViewHeap;
// ... crear el heap ...
D3D12_CPU_DESCRIPTOR_HANDLE DescriptorView = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();
UINT HeapIncrementSize = Device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
for (UINT FrameIndex = 0; FrameIndex < kFrameCount; ++FrameIndex)
{
Device->CreateRenderTargetView(
RenderTargets[FrameIndex].Get(),
nullptr,
DescriptorView
);
DescriptorView.ptr += HeapIncrementSize;
}Así podrías usar los descriptores render target:
UINT CurrentFrameIndex = ...; // el render target actual
D3D12_CPU_DESCRIPTOR_HANDLE RenderTargetView = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();
RenderTargetView.ptr += ((SIZE_T)CurrentFrameIndex) * Device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
D3D12_CPU_DESCRIPTOR_HANDLE DepthStencilView = ...;
CommandList->OMSetRenderTargets(
1, // número de render targets
&RenderTargetView,
FALSE, // RTsSingleHandleToDescriptorRange
&DepthStencilView
);Descriptor para Constant Buffer
Un constant buffer es un recurso que no cambia a lo largo de la ejecución del pipeline.
Ejemplo típico son las matrices de transformación, la dirección de la luz, el tiempo transcurrido, etc.,
Un constant buffer es un recurso que puede cambiar en cada frame, pero no durante un mismo frame. Es decir, es constante con respecto a la ejecución del pipeline.
struct FSomeConstants {
XMMATRIX MVP;
XMFLOAT3 LightDir;
};
const UINT SizeInBytes = (sizeof(FSomeConstants) + 256) & ~255;
// es un requisito que, para reservar memoria de un constant buffer, la cantidad de memoria a reservar debe ser múltiplo de 256
FSomeConstants SomeConstants;
SomeConstants.MVP = ...;
SomeConstants.LightPos = ...;
ComPtr<ID3D12Resource> ContantBuffer;
// reservar memoria y copiar SomeConstant a ConstantBuffer.
ComPtr<ID3D12DescriptorHeap> ConstantBufferDescriptorHeap;
// crear un descriptor heap para alojar el descriptor
// Crear el descriptor
D3D12_CONSTANT_BUFFER_VIEW_DESC ConstantBufferViewDesc{};
ConstantBufferViewDesc.BufferLocation = ConstantBuffer->GetGPUVirtualAddress();
ConstantBufferViewDesc.SizeInBytes = SizeInBytes; // debe ser múltiplo de 256
Device->CreateConstantBufferView(&ConstantBufferViewDesc, ConstantBufferDescriptorHeap->GetCPUDescriptorHandleForHeapStart());¿Dónde usamos este descriptor? Este descriptor debemos pasárselo a los shaders de algún modo para que puedan hacer uso del recurso.
Lo veremos en siguientes tutoriales.
Código para el proyecto
Añade el siguiente código al proyecto:
// DemoApp.h
class DemoApp
{
static const UINT kFrameCount = 2;
// ...
private:
// ...
ComPtr<ID3D12DescriptorHeap> RenderTargetViewHeap;
ComPtr<ID3D12Resource> RenderTargets[kFrameCount];
void CreateRenderTargets();
}void DemoApp::CreateRenderTargets()
{
/* RenderTargetHeap */
D3D12_DESCRIPTOR_HEAP_DESC DescriptorHeapDesc{};
DescriptorHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
DescriptorHeapDesc.NodeMask = 0;
DescriptorHeapDesc.NumDescriptors = kFrameCount;
DescriptorHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV;
Device->CreateDescriptorHeap(&DescriptorHeapDesc, IID_PPV_ARGS(&RenderTargetViewHeap));
for (UINT FrameIndex = 0; FrameIndex < kFrameCount; ++FrameIndex)
{
/*
@TODO:
Crearemos el recurso RenderTargets[FrameIndex]
en siguientes tutoriales. En concreto, el relacionado
con Swapchain.
*/
/* Crear el descriptor para RenderTargets[FrameIndex] */
D3D12_RENDER_TARGET_VIEW_DESC RTDesc{};
RTDesc.ViewDimension = D3D12_RTV_DIMENSION_TEXTURE2D;
RTDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
RTDesc.Texture2D.MipSlice = 0;
RTDesc.Texture2D.PlaneSlice = 0;
D3D12_CPU_DESCRIPTOR_HANDLE DestDescriptor = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();
DestDescriptor.ptr += ((SIZE_T)FrameIndex) * Device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
Device->CreateRenderTargetView(RenderTargets[FrameIndex].Get(), &RTDesc, DestDescriptor);
}
}Siguiente paso
Con los recursos creados y listos para usarse por el pipeline, es hora de configurar el pipeline.
Pipeline
Para que podamos pintar algo por pantalla necesitamos configurar el pipeline. En este tutorial veremos como compilar los shaders y cambiar los parámetros del pipeline.
Pipeline State
El pipeline en DX12 tiene la siguiente pinta:
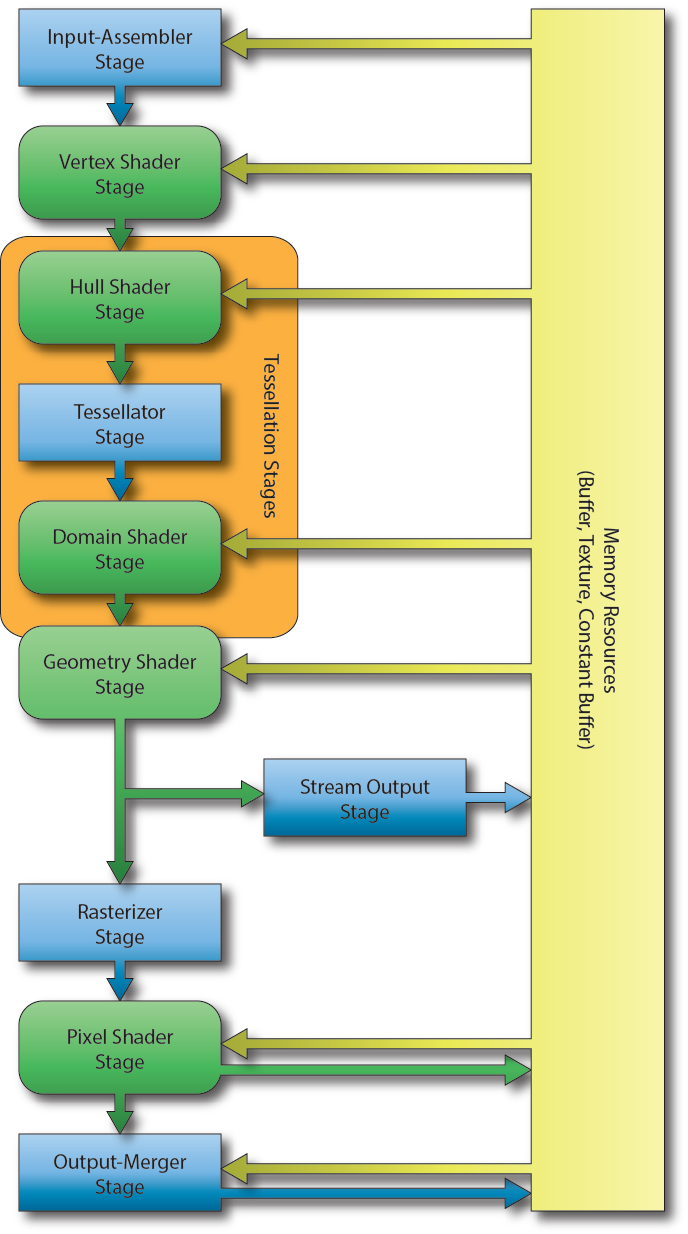
Configurar el pipeline se refiere a:
- Subir los shaders a las etapas programables
- Setear los parámetros de cada etapa fija
El pipeline está encapsulado en la clase ID3D12PipelineState.
Para crear un ID3D12PipelineState se usa la estructura D3D12_GRAPHICS_PIPELINE_STATE_DESC.
ComPtr<ID3D12PipelineState> PipelineState;
D3D12_GRAPHICS_PIPELINE_STATE_DESC PSODesc{};
PSODesc.InputLayout = /* estructura con los parámetros de la etapa Input Assembler */;
PSODesc.VS = /* shader para vertex shader */;
PSODesc.PS = /* shader para pixel shader */;
PSODesc.RasterizerState = /* estructura con los parámetros de la etapa rasterizer */;
PSODesc.BlendState = /* como mezclar colores con transparencias */;
PSODesc.DepthStencilState = /* depth & stencil */;
PSODesc.SampleMask = UINT_MAX; /* The sample mask for the blend state */
PSODesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE;
PSODesc.NumRenderTargets = 1;
PSODesc.RTVFormats[0] = DXGI_FORMAT_R8G8B8A8_UNORM;
PSODesc.SampleDesc.Count = 1;
Device->CreateGraphicsPipelineState(&PSODesc, IID_PPV_ARGS(&PipelineState));El objeto ID3D12PipelineState se usa cuando empiezas a grabar comandos, indicando qué estado debe tener el pipeline cuando ejecute los comandos:
ComPtr<ID3D12CommandAllocator> CommandAllocator;
ComPtr<ID3D12GraphicsCommandList> CommandList;
// ...
ComPtr<ID3D12PipelineState> PipelineState;
// ...
CommandAllocator->Reset();
CommandList->Reset(CommandAllocator.Get(), PipelineState.Get());
// ... grabar comandos ...
CommandList->Close();También se puede cambiar el estado del pipeline explícitamente en cualquier punto de la ejecución:
CommandList->SetPipelineState(PipelineState.Get());Vamos a ver como configurar el pipeline.
Input Layout
Tenemos el siguiente buffer de vértices:
struct Vertex
{
XMFLOAT3 Position;
XMFLOAT4 Color;
XMFLOAT2 UV0;
XMFLOAT2 UV1;
};
Vertex Vertices[] = {
// { POS, COLOR, UV0, UV1 }
{ {-0.5f, -0.5f, 0.0f}, {1.0f, 0.0f, 0.0f, 1.0f}, {0.0f, 0.0f}, {0.0f, 0.0f} },
{ {0.5f, -0.5f, 0.0f}, {0.0f, 1.0f, 0.0f, 1.0f}, {1.0f, 0.0f}, {1.0f, 0.0f} },
{ {0.0f, 0.5f, 0.0f}, {0.0f, 0.0f, 1.0f, 1.0f}, {0.5f, 1.0f}, {0.0f, 0.1f} }
};
ComPtr<ID3D12Resource> VertexBuffer;
// Crear vertex buffer. (Lo vimos en tutoriales anteriores)
// Copiar Vertices a este recurso. (Lo vimos en tutoriales anteriores)
D3D12_VERTEX_BUFFER_VIEW VertexBufferView;
// Descriptor de VertexBuffer
// ...
// Entrada de InputAssembler con este vertex buffer
CommandList->IASetVertexBuffers(0, 1, &VertexBufferView);La primera etapa del pipeline, InputAssembler, debe tomar el vertex buffer y pasarle cada uno de los vértices a las siguientes etapas.
Sin ir más lejos, a la etapa inmediatamente siguiente: el Vertex Shader.
// vertex shader (HLSL)
float4 VSMain(float3 position: POSITION, float4 color: COLOR, float2 uv0: UV0, float2 uv1: UV1) : SV_Position
{
// ...
}Sin embargo, el InputAssembler solo ve un vertex buffer que es un buffer contiguo de datos.
¿Cómo sabe que cada vértice ocupa X bytes y, de este modo, poder dividir el buffer en los distintos vértices? ¿Cómo sabe que dentro de cada vértice los primeros 12 bytes corresponden a la posición (4 bytes x 3 floats), los 16 siguientes corresponden al color, etc.,?
Y es más, cada aplicación tendrá su propia estructura Vertex diferente (algunos tendrán un campo para Normal, para coordenadas UV, etc.,).
Hay que indicarle el formato de algún modo al input assembler. Se hace rellenando una estructura de tipo D3D12_INPUT_LAYOUT_DESC.
D3D12_INPUT_ELEMENT_DESC pInputElementDescs[] = {
// SemanticName; SemanticIndex; Format; InputSlot; AlignedByteOffset; InputSlotClass; InstanceDataStepRate;
{"POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0},
{"COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 0, 3 * 4, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0},
{"UV0", 0, DXGI_FORMAT_R32G32_FLOAT, 0, 3 * 4 + 4 * 4, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0},
{"UV1", 1, DXGI_FORMAT_R32G32_FLOAT, 0, 3 * 4 + 4 * 4 + 2 * 2, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0}
};
D3D12_INPUT_LAYOUT_DESC InputLayout{};
InputLayout.NumElements = 4;
InputLayout.pInputElementDescs = pInputElementDescs;
D3D12_GRAPHICS_PIPELINE_STATE_DESC PSODesc{};
PSODesc.InputLayout = InputLayout;
/* ... */
Device->CreateGraphicsPipelineState(&PSODesc, IID_PPV_ARGS(&PipelineState));Shaders
Para las etapas programables hay que compilar un shader.
El resultado de la compilación será un bloque de código representado por la clase ID3Blob:
ComPtr<ID3DBlob> ShaderBlob = LoadShader(...); // definimos esta función enseguida
````
Partiendo de este bloque de código creamos una referencia al shader:
````cpp
D3D12_SHADER_BYTECODE ShaderBytecode;
ShaderBytecode.pShaderBytecode = ShaderBlob->GetBufferPointer();
ShaderBytecode.BytecodeLength = ShaderBlob->GetBufferSize();
// usar ShaderBytecode allí dónde necesite una referencia al shaderPodemos compilar un shader offline usando el compilador que trae de seria Visual Studio. También podemos compilarlo en runtime usando la función D3DCompileFromFile:
ComPtr<ID3DBlob> DemoApp::LoadShader(LPCWSTR Filename, LPCSTR EntryPoint, LPCSTR Target)
{
HRESULT hr;
ComPtr<ID3DBlob> ShaderBlob; // chunk of memory
hr = D3DCompileFromFile(
Filename, // FileName,
nullptr, nullptr, // MacroDefines, Includes,
EntryPoint, // FunctionEntryPoint,
Target, // Target: "vs_5_0", "ps_5_0", "vs_5_1", "ps_5_1"
D3DCOMPILE_DEBUG | D3DCOMPILE_SKIP_OPTIMIZATION, // Compile flags
0, // Flags2
&ShaderBlob, // Code
nullptr // Error
);
if (FAILED(hr))
{
OutputDebugString("[ERROR] D3DCompileFromFile -- Vertex shader");
}
return ShaderBlob;
}Vertex Shader & Pixel Shader
Un fichero de shaders de ejemplo:
// shaders.hlsl
struct PSInput
{
float4 position : SV_POSITION;
float4 color : COLOR;
};
PSInput VSMain(float4 position : POSITION, float4 color : COLOR)
{
PSInput result;
result.position = position;
result.color = color;
return result;
}
float4 PSMain(PSInput input) : SV_TARGET
{
return input.color;
}Cargar los vertex y pixel shaders:
/* Shaders */
ComPtr<ID3DBlob> VertexBlob = LoadShader(L"shaders.hlsl", "VSMain", "vs_5_1");
D3D12_SHADER_BYTECODE VertexShaderBytecode;
VertexShaderBytecode.pShaderBytecode = VertexBlob->GetBufferPointer();
VertexShaderBytecode.BytecodeLength = VertexBlob->GetBufferSize();
ComPtr<ID3DBlob> PixelBlob = LoadShader(L"shaders.hlsl", "PSMain", "ps_5_1");
D3D12_SHADER_BYTECODE PixelShaderBytecode;
PixelShaderBytecode.pShaderBytecode = PixelBlob->GetBufferPointer();
PixelShaderBytecode.BytecodeLength = PixelBlob->GetBufferSize();Y para el pipeline state:
D3D12_GRAPHICS_PIPELINE_STATE_DESC PSODesc{};
// ...
PSODesc.VS = VertexShaderBytecode;
PSODesc.PS = PixelShaderBytecode;
// ...Rasterizer Stage
La etapa de rasterización toma la representación gráfica 3D y genera los fragmentos que luego serán "coloreados" por el pixel shader.
D3D12_RASTERIZER_DESC RasterizerState{};
RasterizerState.FillMode = D3D12_FILL_MODE_SOLID;
RasterizerState.CullMode = D3D12_CULL_MODE_BACK;
RasterizerState.FrontCounterClockwise = FALSE;
RasterizerState.DepthBias = D3D12_DEFAULT_DEPTH_BIAS;
RasterizerState.DepthBiasClamp = D3D12_DEFAULT_DEPTH_BIAS_CLAMP;
RasterizerState.SlopeScaledDepthBias = D3D12_DEFAULT_SLOPE_SCALED_DEPTH_BIAS;
RasterizerState.DepthClipEnable = TRUE;
RasterizerState.MultisampleEnable = FALSE;
RasterizerState.AntialiasedLineEnable = FALSE;
RasterizerState.ForcedSampleCount = 0;
RasterizerState.ConservativeRaster = D3D12_CONSERVATIVE_RASTERIZATION_MODE_OFF;
D3D12_GRAPHICS_PIPELINE_STATE_DESC PSODesc{};
// ...
PSODesc.RasterizerState = RasterizerState;
// ...Los campos son bastante autodescriptivos. Aquí la documentación oficial.
Depth & Stencil
Para el proyecto de ejemplo no usaremos depth/stencil:
/* Depth Stencil */
D3D12_DEPTH_STENCIL_DESC DepthStencilState{};
DepthStencilState.DepthEnable = FALSE;
DepthStencilState.StencilEnable = FALSE;En futuros tutoriales lo veremos.
Blend State
La fase de blend en el pipeline ocurre en la etapa Output Merger.
¿Qué es blending? Una vez renderizado los fragmentos en la etapa Rasterizer y "coloreados" en la etapa Pixel Shader tenemos que decidir que color final tendra el pixel.
Un pixel puede contener varios fragmentos, cada uno con un color, ¿cómo los mezclamos?
La estructura D3D12_BLEND_DESC contiene la respuesta.
D3D12_BLEND_DESC BlendState{};
// ... rellenar la estructura ...
D3D12_GRAPHICS_PIPELINE_STATE_DESC PSODesc{};
// ...
PSODesc.BlendState = BlendState;
// ...La estructura tiene la siguiente declaración:
typedef struct D3D12_BLEND_DESC {
BOOL AlphaToCoverageEnable;
BOOL IndependentBlendEnable;
D3D12_RENDER_TARGET_BLEND_DESC RenderTarget[8];
} D3D12_BLEND_DESC;El primer campo de la estructura indica si queremos AlphaToCoverage como una técnica de multisampling.
El segundo si solo queremos hacer blend en el primer render target (recuerda que output merger tiene hasta hasta 8 render targets como salida). En general pondrás ambos a FALSE, más información en la documentación oficial.
El último campo, y más importante, es un array de D3D12_RENDER_TARGET_BLEND_DESC indicando que operación de blend hacer en cada render target. El primer elemento del array describe la operación de blend para el primer render target, el segundo para el segundo y así sucesivamente.
typedef struct D3D12_RENDER_TARGET_BLEND_DESC {
BOOL BlendEnable;
BOOL LogicOpEnable;
D3D12_BLEND SrcBlend;
D3D12_BLEND DestBlend;
D3D12_BLEND_OP BlendOp;
D3D12_BLEND SrcBlendAlpha;
D3D12_BLEND DestBlendAlpha;
D3D12_BLEND_OP BlendOpAlpha;
D3D12_LOGIC_OP LogicOp;
UINT8 RenderTargetWriteMask;
} D3D12_RENDER_TARGET_BLEND_DESC;Básicamente tenemos dos colores y queremos mezclarlos siguiendo la siguiente combinación lineal (para el valor del color y para el alpha):
$$ C_{final} = \gamma_{source} C_{source} + \gamma_{dest} C_{dest} $$
$$ \alpha_{final} = \tau_{source} \alpha_{source} + \tau_{dest} \alpha_{dest} $$
Esto es precisamente lo que describe la estructura D3D12_RENDER_TARGET_BLEND_DESC los parámetros $\alpha$ y $\tau$ así como la operación (suma, resta, etc.,).
En nuestro caso no queremos usar blend así que vamos a desactivarlo. Desgraciadamente tenemos que ser explícitos y rellenar todos los campos:
D3D12_BLEND_DESC BlendState{};
BlendState.AlphaToCoverageEnable = FALSE;
BlendState.IndependentBlendEnable = FALSE;
const D3D12_RENDER_TARGET_BLEND_DESC DefaultRenderTargetBlendDesc =
{
FALSE,FALSE,
D3D12_BLEND_ONE, D3D12_BLEND_ZERO, D3D12_BLEND_OP_ADD,
D3D12_BLEND_ONE, D3D12_BLEND_ZERO, D3D12_BLEND_OP_ADD,
D3D12_LOGIC_OP_NOOP,
D3D12_COLOR_WRITE_ENABLE_ALL,
};
for (UINT i = 0; i < D3D12_SIMULTANEOUS_RENDER_TARGET_COUNT; ++i)
{
BlendState.RenderTarget[i] = DefaultRenderTargetBlendDesc;
} Root Signature
En tutoriales anteriores hemos visto como crear un recurso constant buffer y un descriptor para el mismo.
struct FSomeConstants {
XMMATRIX MVP;
XMFLOAT3 LightDir;
};
FSomeConstants SomeConstants;
SomeConstants.MVP = ...;
SomeConstants.LightPos = ...;
// En anterior tutoriales vimos como crear un recurso y obtener un descriptor:
ComPtr<ID3D12DescriptorHeap> ConstantBufferDescriptorHeap;
//...
D3D12_CPU_DESCRIPTOR_HANDLE ConstantBufferDescriptor = ConstantBufferDescriptorHeap->GetCPUDescriptorHandleForHeapStart();¿Cómo pasamos dicho descriptor al shader?
float4x4 MVP; // <-- deberiamos usar el descriptor ConstantBufferDescriptor aquí
float3 LightDir; // <-- y aquí también
float4 VSMain(float4 pos: POSITION, float4: COLOR): SV_POSITION
{
// ...
}
float4 PSMain(float pos: SV_Position): SV_TARGET
{
// ...
}La clave está en indicar en el shader que esos valores están alojados en un constant buffer y además indicar en qué registro está el descriptor:
cbuffer SomeConstants : register(b0)
{
float4x4 MVP;
float3 LightDir;
}
float4 VSMain(float4 pos: POSITION, float4: COLOR): SV_POSITION
{
// ...
}
float4 PSMain(float pos: SV_Position): SV_TARGET
{
// ...
}Desde el lado del shader hemos dicho que esas constantes (MVP y LightDir) están alojadas en un buffer constante y que además el descriptor que describe dicho buffer será cargado en el registro b0.
Nos queda, desde el lado del código, completar el mapeo. Desde el lado de la aplicación tenemos que indicar que el descriptor ConstantBufferDescriptor tiene que ser cargado en el registro b0.
¿Por qué el registro b0? Los registros b0, b1, ... bN se usan para constantes. En este ejemplo podríamos haber usado cualquier registro bX. Los registros t0, t1, ... tN se usan para texturas y los registros s0, s1, ... sN para samplers.
Para completar el mapeo desde el lado del código se usa RootSignature.
RootSignature indica que descriptores van a qué registros.
D3D12_ROOT_SIGNATURE_DESC RootSignatureDesc{};
RootSignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT;
// el InputAssembler va a tomar como entrada un vertex buffer
RootSignatureDesc.NumParameters = 0;
RootSignatureDesc.pParameters = nullptr;
// en este campo iría un array de parámetros.
// cara parámetro empareja un descriptor con un registro
// en nuestro ejemplo uno de los parámetros debería indicar
// ConstantBufferDescriptor <=> b0
RootSignatureDesc.NumStaticSamplers = 0;
RootSignatureDesc.pStaticSamplers = nullptr;
ComPtr<ID3DBlob> Signature; // chunk of memory
ComPtr<ID3DBlob> Error; // chunk of memory
D3D12SerializeRootSignature(&RootSignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1, &Signature, &Error);
ComPtr<ID3D12RootSignature> RootSignature;
Device->CreateRootSignature(0, Signature->GetBufferPointer(), Signature->GetBufferSize(), IID_PPV_ARGS(&RootSignature));Ahora mismo no vamos a pasarle ningún recurso al shader: ni texturas, ni constant buffers, ni nada. Así que nos vale con un root signature vacío tal y como está escrito en el código anterior.
En próximos tutoriales añadiremos parámetros al root signature.
Veremos más adelante el código concreto para añadir parámetros en el root signature.
Código para el proyecto
Añade el siguiente código al proyecto demo:
// DemoApp.h
class DemoApp
{
// ...
private:
/* Pipeline */
ComPtr<ID3DBlob> LoadShader(LPCWSTR Filename, LPCSTR EntryPoint, LPCSTR Target);
ComPtr<ID3D12RootSignature> RootSignature;
ComPtr<ID3D12PipelineState> PipelineState;
void CreateRootSignature();
void CreatePipeline();
};void DemoApp::CreateRootSignature()
{
D3D12_ROOT_SIGNATURE_DESC SignatureDesc{};
SignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT;
SignatureDesc.NumParameters = 0;
SignatureDesc.NumStaticSamplers = 0;
ComPtr<ID3DBlob> Signature;
ComPtr<ID3DBlob> Error;
D3D12SerializeRootSignature(&SignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1_0, &Signature, &Error);
Device->CreateRootSignature(0, Signature->GetBufferPointer(), Signature->GetBufferSize(), IID_PPV_ARGS(&RootSignature));
}
void DemoApp::CreatePipeline()
{
/* Shaders */
ComPtr<ID3DBlob> VertexBlob = LoadShader(L"shaders.hlsl", "VSMain", "vs_5_1");
D3D12_SHADER_BYTECODE VertexShaderBytecode;
VertexShaderBytecode.pShaderBytecode = VertexBlob->GetBufferPointer();
VertexShaderBytecode.BytecodeLength = VertexBlob->GetBufferSize();
ComPtr<ID3DBlob> PixelBlob = LoadShader(L"shaders.hlsl", "PSMain", "ps_5_1");
D3D12_SHADER_BYTECODE PixelShaderBytecode;
PixelShaderBytecode.pShaderBytecode = PixelBlob->GetBufferPointer();
PixelShaderBytecode.BytecodeLength = PixelBlob->GetBufferSize();
/* Input Layout */
D3D12_INPUT_ELEMENT_DESC pInputElementDescs[] = {
// SemanticName; SemanticIndex; Format; InputSlot; AlignedByteOffset; InputSlotClass; InstanceDataStepRate;
{"POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0},
{"COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 0, 3 * 4, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0}
};
D3D12_INPUT_LAYOUT_DESC InputLayout{};
InputLayout.NumElements = 2;
InputLayout.pInputElementDescs = pInputElementDescs;
/* Rasterizer Stage */
D3D12_RASTERIZER_DESC RasterizerState{};
RasterizerState.FillMode = D3D12_FILL_MODE_SOLID;
RasterizerState.CullMode = D3D12_CULL_MODE_BACK;
RasterizerState.FrontCounterClockwise = FALSE;
RasterizerState.DepthBias = D3D12_DEFAULT_DEPTH_BIAS;
RasterizerState.DepthBiasClamp = D3D12_DEFAULT_DEPTH_BIAS_CLAMP;
RasterizerState.SlopeScaledDepthBias = D3D12_DEFAULT_SLOPE_SCALED_DEPTH_BIAS;
RasterizerState.DepthClipEnable = TRUE;
RasterizerState.MultisampleEnable = FALSE;
RasterizerState.AntialiasedLineEnable = FALSE;
RasterizerState.ForcedSampleCount = 0;
RasterizerState.ConservativeRaster = D3D12_CONSERVATIVE_RASTERIZATION_MODE_OFF;
/* Blend State */
D3D12_BLEND_DESC BlendState{};
BlendState.AlphaToCoverageEnable = FALSE;
BlendState.IndependentBlendEnable = FALSE;
const D3D12_RENDER_TARGET_BLEND_DESC DefaultRenderTargetBlendDesc =
{
FALSE,FALSE,
D3D12_BLEND_ONE, D3D12_BLEND_ZERO, D3D12_BLEND_OP_ADD,
D3D12_BLEND_ONE, D3D12_BLEND_ZERO, D3D12_BLEND_OP_ADD,
D3D12_LOGIC_OP_NOOP,
D3D12_COLOR_WRITE_ENABLE_ALL,
};
for (UINT i = 0; i < D3D12_SIMULTANEOUS_RENDER_TARGET_COUNT; ++i)
{
BlendState.RenderTarget[i] = DefaultRenderTargetBlendDesc;
}
/* Depth Stencil */
D3D12_DEPTH_STENCIL_DESC DepthStencilState{};
DepthStencilState.DepthEnable = FALSE;
DepthStencilState.StencilEnable = FALSE;
/* Pipeline */
D3D12_GRAPHICS_PIPELINE_STATE_DESC PSODesc{};
PSODesc.InputLayout = InputLayout;
PSODesc.pRootSignature = RootSignature.Get();
PSODesc.VS = VertexShaderBytecode;
PSODesc.PS = PixelShaderBytecode;
PSODesc.RasterizerState = RasterizerState;
PSODesc.BlendState = BlendState;
PSODesc.DepthStencilState = DepthStencilState;
PSODesc.SampleMask = UINT_MAX;
PSODesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE;
PSODesc.NumRenderTargets = 1;
PSODesc.RTVFormats[0] = DXGI_FORMAT_R8G8B8A8_UNORM;
PSODesc.SampleDesc.Count = 1;
Device->CreateGraphicsPipelineState(&PSODesc, IID_PPV_ARGS(&PipelineState));
}El constructor quedaría así:
DemoApp::DemoApp()
{
CreateDevice();
CreateQueues();
CreateFence();
//CreateSwapchain(hWnd, Width, Height);
CreateRenderTargets();
CreateRootSignature();
CreatePipeline();
}Siguientes pasos
Configurado el pipeline vamos a ver como mostrar cosas por pantalla.
Swapchain
Swapchain permite mostrar por pantalla los render target generados por la GPU. En este tutorial ¡por fin mostraremos algo por pantalla!
El resultado final del pipeline es un render target que queremos mostrar por pantalla.
Si creamos un único recurso render target tendremos el problema del flickering. Básicamente es que lo que mostramos en pantalla se está calculando al mismo tiempo.
Para ello, normalmente usamos dos render targets. Solo uno de ellos se muestra por pantalla y el otro se usa como salida del pipeline.
Cuando el render target está calculado entonces hacemos flip y mostramos el render target recién calculado mientras que usamos el que previamente se mostraba por pantalla para calcular el siguiente frame.
A este técnica se le suele denominar double buffering. Podemos usar más de dos render targets (con tres sería triple buffering).
La buena noticia es que todo este proceso de gestionar los render target y hacer los flip lo hace DX12 por nosotros con IDXGISwapChain.
DXGI_SWAP_CHAIN_DESC1 SwapchainDesc{};
SwapchainDesc.BufferCount = 2;
SwapchainDesc.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT;
SwapchainDesc.Width = Width;
SwapchainDesc.Height = Height;
SwapchainDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
SwapchainDesc.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD;
SwapchainDesc.SampleDesc.Count = 1;
ComPtr<IDXGISwapChain1> SwapchainTemp;
Factory->CreateSwapChainForHwnd(
CommandQueue.Get(), // swap chain forces flush when does flip
hWnd,
&SwapchainDesc,
nullptr, // pFullscreenDesc
nullptr, // pRestrictToOutput
&SwapchainTemp
);
ComPtr<IDXGISwapChain3> Swapchain;
SwapchainTemp.As(&Swapchain);Render Target
Swapchain ha creado por nosotros los recursos render target. Podemos usar el método GetBuffer para obtenerlos.
ComPtr<ID3D12Resource> RenderTargets[kFrameCount]; // extracted from Swapchain
for (UINT FrameIndex = 0; FrameIndex < kFrameCount; ++FrameIndex)
{
Swapchain->GetBuffer(FrameIndex, IID_PPV_ARGS(&RenderTargets[FrameIndex]));
}Completando el codigo del proyecto
En el código del proyecto tenemos el siguiente código pendiente del anterior tutorial sobre descriptores:
void DemoApp::CreateRenderTargets()
{
/* RenderTargetHeap */
// ...
for (UINT FrameIndex = 0; FrameIndex < kFrameCount; ++FrameIndex)
{
/*
@TODO:
Crearemos el recurso RenderTargets[FrameIndex]
en siguientes tutoriales. En concreto, el relacionado
a Swapchain.
*/
/* Crear el descriptor para RenderTargets[FrameIndex] */
// ...
}
}Ahora podemos completarlo con:
void DemoApp::CreateRenderTargets()
{
/* RenderTargetHeap */
// ...
for (UINT FrameIndex = 0; FrameIndex < kFrameCount; ++FrameIndex)
{
// Obtener el resource
Swapchain->GetBuffer(FrameIndex, IID_PPV_ARGS(&RenderTargets[FrameIndex]));
/* Crear el descriptor para RenderTargets[FrameIndex] */
// ...
}
}Presentar por pantalla
Para presentar por pantalla el back render target del swapchain se usa el método Present.
El siguiente código de ejemplo ejemplifica como se usaría:
// para cada frame
while(true)
{
// grabar los comandos para renderizar
RecordCommandList();
// subir los comandos a la GPU para que se ejecuten
ID3D12CommandList* ppCommandLists[] = { CommandList.Get() };
CommandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
// encolar comando presentar por pantalla
Swapchain->Present(1, 0);
FlushAndWait(); // Sync CPU/GPU
}Para que el pipeline escriba en el back render target del swapchain usamos el método GetCurrentBackBufferIndex()
void RecordCommandList() {
UINT BackFrameIndex = Swapchain->GetCurrentBackBufferIndex();
// ...
// CommandList->...., CommandList->...., CommandList->....
// ...
// Obtener el render target descriptor para este BackFrameIndex
D3D12_CPU_DESCRIPTOR_HANDLE RenderTargetDescriptor = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();
RenderTargetDescriptor.ptr += ((SIZE_T)BackFrameIndex) * Device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
CommandList->OMSetRenderTargets(
1,
&RenderTargetDescriptor,
FALSE,
nullptr // depth/stencil
);
}Añadir Swapchain al proyecto
Y después de ocho tutoriales nuestro proyecto por fin hace algo. Que la pantalla se vea de color rojo. ¡Bravísimo!
El código completo sería:
// DemoApp.h
#pragma once
// ComPtr<T>
#include <wrl.h>
using namespace Microsoft::WRL;
// DirectX 12 specific headers.
#include <d3d12.h>
#include <dxgi1_6.h>
#include <d3dcompiler.h>
#include <DirectXMath.h>
using namespace DirectX;
static const UINT8 kFrameCount = 2;
class DemoApp
{
public:
DemoApp(HWND hWnd, UINT Width, UINT Height);
/* Run */
void Tick();
private:
/* Device */
ComPtr<IDXGIFactory4> Factory;
ComPtr<ID3D12Device> Device;
void CreateDevice();
/* Queue */
ComPtr<ID3D12CommandQueue> CommandQueue;
ComPtr<ID3D12CommandAllocator> CommandAllocator;
ComPtr<ID3D12GraphicsCommandList> CommandList;
void CreateQueues();
/* Fences */
ComPtr<ID3D12Fence> Fence;
HANDLE FenceEvent;
UINT64 FenceValue;
void CreateFence();
void FlushAndWait();
/* Pipeline */
/* -- para este ejemplo no necesitamos pipeline ni root signature */
ComPtr<ID3DBlob> LoadShader(LPCWSTR Filename, LPCSTR EntryPoint, LPCSTR Target);
ComPtr<ID3D12RootSignature> RootSignature;
ComPtr<ID3D12PipelineState> PipelineState;
void CreateRootSignature();
void CreatePipeline();
/* Swapchain */
ComPtr<IDXGISwapChain3> Swapchain;
ComPtr<ID3D12DescriptorHeap> RenderTargetViewHeap;
ComPtr<ID3D12Resource> RenderTargets[kFrameCount]; // extracted from Swapchain
void CreateRenderTargets();
void CreateSwapchain(HWND hWnd, UINT Width, UINT Height);
/* Record command list for render */
void RecordCommandList();
};#include "DemoApp.h"
#include "GPUMem.h"
DemoApp::DemoApp(HWND hWnd, UINT Width, UINT Height)
{
CreateDevice();
CreateQueues();
CreateFence();
CreateSwapchain(hWnd, Width, Height);
CreateRenderTargets();
//CreateRootSignature();
//CreatePipeline();
}
void DemoApp::CreateDevice()
{
CreateDXGIFactory1(IID_PPV_ARGS(&Factory));
ComPtr<IDXGIAdapter1> Adapter;
bool bAdapterFound = false;
for (UINT AdapterIndex = 0;
!bAdapterFound && Factory->EnumAdapters1(AdapterIndex, &Adapter) != DXGI_ERROR_NOT_FOUND;
++AdapterIndex)
{
DXGI_ADAPTER_DESC1 AdapterDesc;
Adapter->GetDesc1(&AdapterDesc);
if (AdapterDesc.Flags & DXGI_ADAPTER_FLAG_SOFTWARE)
{
continue;
}
HRESULT hr;
hr = D3D12CreateDevice(Adapter.Get(), D3D_FEATURE_LEVEL_11_0, _uuidof(ID3D12Device), nullptr);
if (SUCCEEDED(hr))
{
bAdapterFound = true;
}
}
D3D12CreateDevice(Adapter.Get(), D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&Device));
}
void DemoApp::CreateQueues()
{
// CommandQueue
D3D12_COMMAND_QUEUE_DESC CommandQueueDesc{};
CommandQueueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
CommandQueueDesc.NodeMask = 0;
CommandQueueDesc.Priority = D3D12_COMMAND_QUEUE_PRIORITY_NORMAL;
CommandQueueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
Device->CreateCommandQueue(&CommandQueueDesc, IID_PPV_ARGS(&CommandQueue));
// Command Allocator
Device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(&CommandAllocator));
// Command List
ID3D12PipelineState* InitialState = nullptr;
Device->CreateCommandList(
0,
D3D12_COMMAND_LIST_TYPE_DIRECT,
CommandAllocator.Get(),
InitialState,
IID_PPV_ARGS(&CommandList)
);
CommandList->Close();
}
void DemoApp::CreateFence()
{
FenceValue = 0;
Device->CreateFence(FenceValue, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&Fence));
FenceEvent = CreateEvent(nullptr, FALSE, FALSE, nullptr);
}
void DemoApp::FlushAndWait()
{
const UINT64 FenceValueToSignal = FenceValue;
CommandQueue->Signal(Fence.Get(), FenceValueToSignal);
++FenceValue;
if (Fence->GetCompletedValue() < FenceValueToSignal)
{
Fence->SetEventOnCompletion(FenceValueToSignal, FenceEvent);
WaitForSingleObject(FenceEvent, INFINITE);
}
}
ComPtr<ID3DBlob> DemoApp::LoadShader(LPCWSTR Filename, LPCSTR EntryPoint, LPCSTR Target)
{
/* no lo usaremos en este ejemplo */
}
void DemoApp::CreateRootSignature()
{
/* no lo usaremos en este ejemplo */
}
void DemoApp::CreatePipeline()
{
/* no lo usaremos en este ejemplo */
}
void DemoApp::CreateRenderTargets()
{
/* RenderTargetHeap */
D3D12_DESCRIPTOR_HEAP_DESC DescriptorHeapDesc{};
DescriptorHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
DescriptorHeapDesc.NodeMask = 0;
DescriptorHeapDesc.NumDescriptors = kFrameCount;
DescriptorHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV;
Device->CreateDescriptorHeap(&DescriptorHeapDesc, IID_PPV_ARGS(&RenderTargetViewHeap));
for (UINT FrameIndex = 0; FrameIndex < kFrameCount; ++FrameIndex)
{
Swapchain->GetBuffer(FrameIndex, IID_PPV_ARGS(&RenderTargets[FrameIndex]));
D3D12_RENDER_TARGET_VIEW_DESC RTDesc{};
RTDesc.ViewDimension = D3D12_RTV_DIMENSION_TEXTURE2D;
RTDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
RTDesc.Texture2D.MipSlice = 0;
RTDesc.Texture2D.PlaneSlice = 0;
D3D12_CPU_DESCRIPTOR_HANDLE DestDescriptor = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();
DestDescriptor.ptr += ((SIZE_T)FrameIndex) * Device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
Device->CreateRenderTargetView(RenderTargets[FrameIndex].Get(), &RTDesc, DestDescriptor);
}
}
void DemoApp::CreateSwapchain(HWND hWnd, UINT Width, UINT Height)
{
/* Swapchain */
DXGI_SWAP_CHAIN_DESC1 SwapchainDesc{};
SwapchainDesc.BufferCount = 2;
SwapchainDesc.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT;
SwapchainDesc.Width = Width;
SwapchainDesc.Height = Height;
SwapchainDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
SwapchainDesc.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD;
SwapchainDesc.SampleDesc.Count = 1;
ComPtr<IDXGISwapChain1> SwapchainTemp;
Factory->CreateSwapChainForHwnd(
CommandQueue.Get(), // swap chain forces flush when does flip
hWnd,
&SwapchainDesc,
nullptr,
nullptr,
&SwapchainTemp
);
SwapchainTemp.As(&Swapchain);
}
void DemoApp::RecordCommandList()
{
const UINT BackFrameIndex = Swapchain->GetCurrentBackBufferIndex();
CommandAllocator->Reset();
CommandList->Reset(CommandAllocator.Get(), nullptr); // para borrar la pantalla no necesitamos un pipeline
D3D12_CPU_DESCRIPTOR_HANDLE RenderTargetDescriptor = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();
RenderTargetDescriptor.ptr += ((SIZE_T)BackFrameIndex) * Device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
GPUMem::ResourceBarrier(CommandList.Get(), RenderTargets[BackFrameIndex].Get(), D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET);
const FLOAT ClearValue[] = { 1.0f, 0.0f, 0.0f, 1.0f };
CommandList->ClearRenderTargetView(RenderTargetDescriptor, ClearValue, 0, nullptr);
GPUMem::ResourceBarrier(CommandList.Get(), RenderTargets[BackFrameIndex].Get(), D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT);
CommandList->Close();
}
void DemoApp::Tick()
{
RecordCommandList();
ID3D12CommandList* ppCommandLists[] = { CommandList.Get() };
CommandQueue->ExecuteCommandLists(1, ppCommandLists);
Swapchain->Present(1, 0);
FlushAndWait();
}// ...
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE, LPSTR, int nCmdShow)
{
// ...
DemoApp App{hWnd, Width, Height};
// ...
while (true)
{
// ...
App.Tick();
}
}Y nuestro espectacular resultado:
Triángulo
Vamos a usar todo lo aprendido para pintar un triángulo por pantalla. Nuestro Hello World en DX12.
Pipeline & Root Signature
Partiendo del código del tutorial anterior, vamos a completar el código con los métodos para crear pipeline y RootSignature:
// En el tutorial referente al pipeline explicamos todo este código.
ComPtr<ID3DBlob> DemoApp::LoadShader(LPCWSTR Filename, LPCSTR EntryPoint, LPCSTR Target)
{
HRESULT hr;
/* Shaders */
ComPtr<ID3DBlob> ShaderBlob;
hr = D3DCompileFromFile(
Filename, // FileName
nullptr, nullptr, // MacroDefines, Includes,
EntryPoint, // FunctionEntryPoint
Target, // Target: "vs_5_0", "ps_5_0", "vs_5_1", "ps_5_1"
D3DCOMPILE_DEBUG | D3DCOMPILE_SKIP_OPTIMIZATION, // Compile flags
0, // Flags2
&ShaderBlob, // Code
nullptr // Error
);
if (FAILED(hr))
{
OutputDebugString("[ERROR] D3DCompileFromFile -- Vertex shader");
}
return ShaderBlob;
}
void DemoApp::CreateRootSignature()
{
/* RootSignature vacío, no le pasamos decriptores
(ni texturas, ni constant buffer, etc.,) a los shaders */
D3D12_ROOT_SIGNATURE_DESC SignatureDesc{};
SignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT;
SignatureDesc.NumParameters = 0;
SignatureDesc.NumStaticSamplers = 0;
ComPtr<ID3DBlob> Signature;
ComPtr<ID3DBlob> Error;
D3D12SerializeRootSignature(&SignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1_0, &Signature, &Error);
Device->CreateRootSignature(0, Signature->GetBufferPointer(), Signature->GetBufferSize(), IID_PPV_ARGS(&RootSignature));
}
void DemoApp::CreatePipeline()
{
/* Shaders */
ComPtr<ID3DBlob> VertexBlob = LoadShader(L"shaders.hlsl", "VSMain", "vs_5_1");
D3D12_SHADER_BYTECODE VertexShaderBytecode;
VertexShaderBytecode.pShaderBytecode = VertexBlob->GetBufferPointer();
VertexShaderBytecode.BytecodeLength = VertexBlob->GetBufferSize();
ComPtr<ID3DBlob> PixelBlob = LoadShader(L"shaders.hlsl", "PSMain", "ps_5_1");
D3D12_SHADER_BYTECODE PixelShaderBytecode;
PixelShaderBytecode.pShaderBytecode = PixelBlob->GetBufferPointer();
PixelShaderBytecode.BytecodeLength = PixelBlob->GetBufferSize();
/* Input Layout */
// vamos a usar un Vertex con position y color
D3D12_INPUT_ELEMENT_DESC pInputElementDescs[] = {
// SemanticName; SemanticIndex; Format; InputSlot; AlignedByteOffset; InputSlotClass; InstanceDataStepRate;
{"POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0},
{"COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 0, 3 * 4, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0}
};
D3D12_INPUT_LAYOUT_DESC InputLayout{};
InputLayout.NumElements = 2;
InputLayout.pInputElementDescs = pInputElementDescs;
/* Rasterizer Stage */
D3D12_RASTERIZER_DESC RasterizerState{};
RasterizerState.FillMode = D3D12_FILL_MODE_SOLID;
RasterizerState.CullMode = D3D12_CULL_MODE_BACK;
RasterizerState.FrontCounterClockwise = FALSE;
RasterizerState.DepthBias = D3D12_DEFAULT_DEPTH_BIAS;
RasterizerState.DepthBiasClamp = D3D12_DEFAULT_DEPTH_BIAS_CLAMP;
RasterizerState.SlopeScaledDepthBias = D3D12_DEFAULT_SLOPE_SCALED_DEPTH_BIAS;
RasterizerState.DepthClipEnable = TRUE;
RasterizerState.MultisampleEnable = FALSE;
RasterizerState.AntialiasedLineEnable = FALSE;
RasterizerState.ForcedSampleCount = 0;
RasterizerState.ConservativeRaster = D3D12_CONSERVATIVE_RASTERIZATION_MODE_OFF;
/* Blend State */
D3D12_BLEND_DESC BlendState{};
BlendState.AlphaToCoverageEnable = FALSE;
BlendState.IndependentBlendEnable = FALSE;
const D3D12_RENDER_TARGET_BLEND_DESC DefaultRenderTargetBlendDesc =
{
FALSE,FALSE,
D3D12_BLEND_ONE, D3D12_BLEND_ZERO, D3D12_BLEND_OP_ADD,
D3D12_BLEND_ONE, D3D12_BLEND_ZERO, D3D12_BLEND_OP_ADD,
D3D12_LOGIC_OP_NOOP,
D3D12_COLOR_WRITE_ENABLE_ALL,
};
for (UINT i = 0; i < D3D12_SIMULTANEOUS_RENDER_TARGET_COUNT; ++i)
{
BlendState.RenderTarget[i] = DefaultRenderTargetBlendDesc;
}
/* Depth Stencil */
D3D12_DEPTH_STENCIL_DESC DepthStencilState{};
DepthStencilState.DepthEnable = FALSE;
DepthStencilState.StencilEnable = FALSE;
/* Pipeline */
D3D12_GRAPHICS_PIPELINE_STATE_DESC PSODesc{};
PSODesc.InputLayout = InputLayout;
PSODesc.pRootSignature = RootSignature.Get();
PSODesc.VS = VertexShaderBytecode;
PSODesc.PS = PixelShaderBytecode;
PSODesc.RasterizerState = RasterizerState;
PSODesc.BlendState = BlendState;
PSODesc.DepthStencilState = DepthStencilState;
PSODesc.SampleMask = UINT_MAX;
PSODesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE;
PSODesc.NumRenderTargets = 1;
PSODesc.RTVFormats[0] = DXGI_FORMAT_R8G8B8A8_UNORM;
PSODesc.SampleDesc.Count = 1;
Device->CreateGraphicsPipelineState(&PSODesc, IID_PPV_ARGS(&PipelineState));
}Si necesitas repasar dirígete al tutorial sobre el pipeline dónde se explica todo este código.
Crear el Vertex Buffer
Añade los siguientes métodos:
// DemoApp.h
class DemoApp
{
// ...
/* Vertex Buffers */
struct Vertex
{
XMFLOAT3 Position;
XMFLOAT4 Color;
};
ComPtr<ID3D12Resource> VertexBuffer;
D3D12_VERTEX_BUFFER_VIEW VertexBufferView;
void CreateVertexBuffer();
};// DemoApp.cpp
void DemoApp::CreateVertexBuffer()
{
Vertex Vertices[] = {
// { POS, COLOR }
{ {-0.5f, -0.5f, 0.0f}, {1.0f, 0.0f, 0.0f, 1.0f} },
{ {0.5f, -0.5f, 0.0f}, {0.0f, 1.0f, 0.0f, 1.0f} },
{ {0.0f, 0.5f, 0.0f}, {0.0f, 0.0f, 1.0f, 1.0f} }
};
VertexBuffer = GPUMem::Buffer(Device.Get(), sizeof(Vertices), D3D12_HEAP_TYPE_DEFAULT);
ComPtr<ID3D12Resource> UploadBuffer = GPUMem::Buffer(Device.Get(), sizeof(Vertices), D3D12_HEAP_TYPE_UPLOAD);
UINT8* pData;
D3D12_RANGE ReadRange{ 0, 0 };
UploadBuffer->Map(0, &ReadRange, reinterpret_cast<void**>(&pData));
memcpy(pData, Vertices, sizeof(Vertices));
UploadBuffer->Unmap(0, nullptr);
CommandAllocator->Reset();
CommandList->Reset(CommandAllocator.Get(), nullptr);
GPUMem::ResourceBarrier(CommandList.Get(), VertexBuffer.Get(), D3D12_RESOURCE_STATE_GENERIC_READ, D3D12_RESOURCE_STATE_COPY_DEST);
CommandList->CopyResource(VertexBuffer.Get(), UploadBuffer.Get());
CommandList->Close();
ID3D12CommandList* const pCommandList[] = { CommandList.Get() };
CommandQueue->ExecuteCommandLists(1, pCommandList);
VertexBufferView.BufferLocation = VertexBuffer->GetGPUVirtualAddress();
VertexBufferView.SizeInBytes = sizeof(Vertices);
VertexBufferView.StrideInBytes = sizeof(Vertex);
FlushAndWait();
}Y no olvidar llamar a los métodos en el constructor:
DemoApp::DemoApp(HWND hWnd, UINT Width, UINT Height)
{
CreateDevice();
CreateQueues();
CreateFence();
CreateSwapchain(hWnd, Width, Height);
CreateRenderTargets();
CreateRootSignature();
CreatePipeline();
CreateVertexBuffer();
}Todo este código lo explicamos en el tutorial sobre recursos y descriptores.
Comandos para pintar
Modificamos la función *RecordCommandList* con comandos para pintar, principalmente:
- Indicarle cuál es el RenderTarget
- Pasarle el Vertex Buffer
Antes estamos obligados a indicar que región de la pantalla vamos a pintar:
// DemoApp.h
class DemoApp
{
// ...
private:
// ...
/* Viewport and Scissor */
D3D12_VIEWPORT Viewport;
D3D12_RECT ScissorRect;
void SetViewportAndScissorRect(int Width, int Height);
};
// DemoApp.cpp
void DemoApp::SetViewportAndScissorRect(int Width, int Height)
{
Viewport.TopLeftX = 0;
Viewport.TopLeftY = 0;
Viewport.Width = static_cast<FLOAT>(Width);
Viewport.Height = static_cast<FLOAT>(Height);
Viewport.MinDepth = D3D12_MIN_DEPTH;
Viewport.MaxDepth = D3D12_MAX_DEPTH;
ScissorRect.left = 0;
ScissorRect.top = 0;
ScissorRect.right = Width;
ScissorRect.bottom = Height;
}El constructor quedaría así:
DemoApp::DemoApp(HWND hWnd, UINT Width, UINT Height)
{
CreateDevice();
CreateQueues();
CreateFence();
CreateSwapchain(hWnd, Width, Height);
CreateRenderTargets();
CreateRootSignature();
CreatePipeline();
SetViewportAndScissorRect(Width, Height);
CreateVertexBuffer();
}Y actualizamos la lista de comandos:
void DemoApp::RecordCommandList()
{
const UINT BackFrameIndex = Swapchain->GetCurrentBackBufferIndex();
CommandAllocator->Reset();
CommandList->Reset(CommandAllocator.Get(), PipelineState.Get());
D3D12_CPU_DESCRIPTOR_HANDLE RenderTargetDescriptor = RenderTargetViewHeap->GetCPUDescriptorHandleForHeapStart();
RenderTargetDescriptor.ptr += ((SIZE_T)BackFrameIndex) * Device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
GPUMem::ResourceBarrier(CommandList.Get(), RenderTargets[BackFrameIndex].Get(), D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET);
const FLOAT ClearValue[] = { 0.02f, 0.02f, 0.15f, 1.0f };
CommandList->ClearRenderTargetView(RenderTargetDescriptor, ClearValue, 0, nullptr);
CommandList->OMSetRenderTargets(1, &RenderTargetDescriptor, FALSE, nullptr);
CommandList->SetGraphicsRootSignature(RootSignature.Get());
CommandList->RSSetViewports(1, &Viewport);
CommandList->RSSetScissorRects(1, &ScissorRect);
CommandList->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
CommandList->IASetVertexBuffers(0, 1, &VertexBufferView);
CommandList->DrawInstanced(3, 1, 0, 0);
GPUMem::ResourceBarrier(CommandList.Get(), RenderTargets[BackFrameIndex].Get(), D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT);
CommandList->Close();
}Y, por supuesto, no olvidar el shader:
// shaders.hlsl
struct VS2PS
{
float4 position : SV_Position;
float4 color : COLOR;
};
VS2PS VSMain(float3 position : POSITION, float4 color : COLOR)
{
VS2PS vs2ps;
vs2ps.position = float4(position, 1.0);
vs2ps.color = color;
return vs2ps;
}
float4 PSMain(VS2PS vs2ps) : SV_Target
{
return vs2ps.color;
}Si le das a ejecutar tendremos un bonito "hola mundo" en DirectX 12:
Descargar código fuente
Puedes descargar el proyecto en Visual Studio aquí.
Root Signature
Root Signature define que tipo de recursos están vinculados a la pipeline. Si tu pipeline fuera una función, el root signature sería su declaración.
Tus shaders propios usarán una serie de recursos como texturas, constant buffer (por ejemplo matrices de transformación), samplers y otros tipos.
Si tu pipeline fuera una función, sus argumentos serían precisamente esas texturas, constant buffers, samplers, etc., esa "declaración" es precisamente el root signature.
Shaders
Vamos a hacer que rote el triángulo del tutorial anterior.
Primero modificamos el shader:
// shaders.hlsl
cbuffer SomeConstants : register(b0)
{
float4x4 MVP;
}
struct VS2PS
{
float4 position : SV_Position;
float4 color : COLOR;
};
VS2PS VSMain(float3 position : POSITION, float4 color : COLOR)
{
VS2PS vs2ps;
vs2ps.position = mul(MVP, float4(position, 1.0));
vs2ps.color = color;
return vs2ps;
}
float4 PSMain(VS2PS vs2ps) : SV_Target
{
return vs2ps.color;
}Fíjate como la matrix MVP es pasada al shader usando un buffer constante (cbuffer).
Es bastante habitual usar buffer constantes para pasar las matrices de transformación dado que su valor será constante a lo largo de todo el pipeline.
También fíjate como indicamos al shader que el descriptor de ese buffer está mapeado al registro b0.
En otras palabras, la GPU debe cargar en el registro **b0** el descriptor asociado a ese buffer constante.
En el tutorial sobre recursos estuvimos hablando sobre los descriptores y registros.
Si ejecutas ahora verás que no se muestra nada por pantalla, lógico porque MVP aún no le hemos asignado ningún valor.
De hecho si tienes activada [la capa de depuración tal y como vimos en el tutorial sobre adaptadores, la consola te dará el siguiente error:
ID3D12Device::CreateGraphicsPipelineState: Root Signature doesn't match Vertex Shader: Shader CBV descriptor range Es un error bastante descriptivo: nuestro pipeline toma como "argumento" un constant buffer, pero si miras el método CreateRootSignature que hicimos en el tutorial anterior, nuestra root signature está vacía. Dado que la root signature es la "declaración" de los "argumentos" de nuestro pipeline, DX12 te da ese error.
De hecho es en la root signature dónde decimos a DX12 que el descriptor del recurso constant buffer que vamos a crear lo mapeamos al registro b0.
Vamos con ello.
Constant Buffer
Vamos a crear un recurso que aloje nuestro constant buffer. En el tutorial sobre recursos vimos como hacerlo.
Añade el siguiente código:
class DemoApp
{
/* Constant Buffer */
ComPtr<ID3D12Resource> ConstantBufferResource;
ComPtr<ID3D12DescriptorHeap> ConstantBufferDescriptorHeap;
UINT8* pConstantBufferData; // puntero que obtendremos con ConstantBufferResource->Map(...)
void CreateConstantBuffer();
/* Constant Buffer Values */
struct FSomeConstants
{
XMMATRIX MVP;
};
FSomeConstants SomeConstants;
void UpdateConstantBuffer();
};En la implementación:
void DemoApp::CreateConstantBuffer()
{
UINT SizeInBytes = sizeof(FSomeConstants);
// ^^ Esta línea tiene un error que enseguida vamos a corregir
ConstantBufferResource = GPUMem::Buffer(Device.Get(), SizeInBytes, D3D12_HEAP_TYPE_UPLOAD);
D3D12_RANGE ReadRange;
ReadRange.Begin = 0;
ReadRange.End = 0;
ConstantBufferResource->Map(0, &ReadRange, reinterpret_cast<void**>(&pConstantBufferData));
/* Descriptor Heap */
D3D12_DESCRIPTOR_HEAP_DESC DescriptorHeapDesc{};
DescriptorHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE;
DescriptorHeapDesc.NodeMask = 0;
DescriptorHeapDesc.NumDescriptors = 1;
DescriptorHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV; // constant buffer
Device->CreateDescriptorHeap(&DescriptorHeapDesc, IID_PPV_ARGS(&ConstantBufferDescriptorHeap));
/* Create descriptor */
D3D12_CONSTANT_BUFFER_VIEW_DESC ConstantBufferViewDesc{};
ConstantBufferViewDesc.BufferLocation = ConstantBufferResource->GetGPUVirtualAddress();
ConstantBufferViewDesc.SizeInBytes = SizeInBytes;
Device->CreateConstantBufferView(&ConstantBufferViewDesc, ConstantBufferDescriptorHeap->GetCPUDescriptorHandleForHeapStart());
}No olvides llamar a esta función en el constructor:
DemoApp::DemoApp(HWND hWnd, UINT Width, UINT Height)
{
// ...
CreateConstantBuffer();
}Si ejecutas el código verás el siguiente error:
ID3D12Device::CreateConstantBufferView: Size of 64 is invalid. Device requires SizeInBytes be a multiple of 256. [ STATE_CREATION ERROR #650: CREATE_CONSTANT_BUFFER_VIEW_INVALID_DESC]
D3D12: Removing Device.Efectivamente, la GPU requiere que el tamaño de los constant buffer sean múltiplo de 256.
Para ello podemos hacer un truco con operaciones bitwise. Modifica la línea por esta otra:
UINT SizeInBytes = (sizeof(FSomeConstants) + 256) & 256;Si haces una operación AND a nivel de bit con el valor 256 están creando un múltiplo de 256 (pones a 0 los primeros 8 bits, 2 elevado a 8 es 256).
Ya solo nos queda copiar los datos al buffer:
void DemoApp::UpdateConstantBuffer()
{
static float Angle = 0.0f;
Angle += 0.1f;
SomeConstants.MVP = XMMatrixRotationZ(Angle);
memcpy(pConstantBufferData, &SomeConstants, sizeof(FSomeConstants));
}No olvides llamar a este método en el método Tick:
void DemoApp::Tick()
{
UpdateConstantBuffer();
RecordCommandList();
ID3D12CommandList* ppCommandLists[] = { CommandList.Get() };
CommandQueue->ExecuteCommandLists(1, ppCommandLists);
Swapchain->Present(1, 0);
FlushAndWait();
}Root Signature
El estado actual es el siguiente:
- Por un lado tenemos al shader listo para recibir en el registro b0 un descriptor de constant buffer.
- Por otro lado hemos reservado memoria en la GPU y copiado la matriz. Además hemos creado un descriptor listo para cargar en un registro.
¿Qué nos falta?
Nos falta el "pegamento". En concreto nos faltan dos elementos:
- un primer elemento que indique que el registro b0 será cargado con un descriptor de constant buffer (declaración)
- y un segundo elemento que diga que ese constant buffer es precisamente el que hemos creado.
El primer elemento es el root signature. El segundo elemento se hace mediante comandos.
En anteriores tutoriales vimos como crear un root signature vacío:
void DemoApp::CreateRootSignature()
{
/* RootSignature vacío, no le pasamos decriptores
(ni texturas, ni constant buffer, etc.,) a los shaders */
D3D12_ROOT_SIGNATURE_DESC SignatureDesc{};
SignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT;
SignatureDesc.NumParameters = 0;
SignatureDesc.NumStaticSamplers = 0;
ComPtr<ID3DBlob> Signature;
ComPtr<ID3DBlob> Error;
D3D12SerializeRootSignature(&SignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1_0, &Signature, &Error);
Device->CreateRootSignature(0, Signature->GetBufferPointer(), Signature->GetBufferSize(), IID_PPV_ARGS(&RootSignature));
}Vamos a añadir un parámetro:
D3D12_ROOT_PARAMETER RootParameters[1];
/* ... */
D3D12_ROOT_SIGNATURE_DESC SignatureDesc{};
SignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT;
SignatureDesc.NumParameters = _countof(RootParameters);
SignatureDesc.pParameters = RootParameters;Recuerda que el parámetro tiene que decir "en el registro b0 se cargará un constant buffer":
D3D12_ROOT_PARAMETER RootParameters[1];
// este parametro es visible para todos los shaders
RootParameters[0].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
// otros valores podrian ser D3D12_SHADER_VISIBILITY_VERTEX, D3D12_SHADER_VISIBILITY_PIXEL, etc.,
// este parámetro es de tipo constant buffer
RootParameters[0].ParameterType = D3D12_ROOT_PARAMETER_TYPE_CBV;
// otros valores posibles serian D3D12_ROOT_PARAMETER_TYPE_SRV, D3D12_ROOT_PARAMETER_TYPE_32BIT_CONSTANTS, etc.,
RootParameters[0].Descriptor.RegisterSpace = 0; // principalmente para temas de retrocompatibilidad con shaders antiguos
// como es de tipo CBV se cargaran en los registros bX
// en el campo ShaderRegister se indica ese X
RootParameters[0].Descriptor.ShaderRegister = 0; // b0
// para 1 sería b1, para 2 sería b2, etc.,El código completo sería:
void DemoApp::CreateRootSignature()
{
D3D12_ROOT_PARAMETER RootParameters[1];
RootParameters[0].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
RootParameters[0].ParameterType = D3D12_ROOT_PARAMETER_TYPE_CBV;
RootParameters[0].Descriptor.RegisterSpace = 0;
RootParameters[0].Descriptor.ShaderRegister = 0;
D3D12_ROOT_SIGNATURE_DESC SignatureDesc{};
SignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT;
SignatureDesc.NumParameters = _countof(RootParameters);
SignatureDesc.pParameters = RootParameters;
SignatureDesc.NumStaticSamplers = 0;
ComPtr<ID3DBlob> Signature;
ComPtr<ID3DBlob> Error;
D3D12SerializeRootSignature(&SignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1_0, &Signature, &Error);
Device->CreateRootSignature(0, Signature->GetBufferPointer(), Signature->GetBufferSize(), IID_PPV_ARGS(&RootSignature));
}Si ejecutas el código verás que funciona sin errores, sin embargo, ¡aún no le hemos indicado el valor que debe cargarse en el registro b0!
Envía un comando indicando que valor debe ser cargado en el registro b0.
void DemoApp::RecordCommandList()
{
/* ... */
CommandList->SetGraphicsRootConstantBufferView(
0, /* RootParameterIndex */
ConstantBufferResource->GetGPUVirtualAddress() /* BufferLocation */
);
CommandList->DrawInstanced(3, 1, 0, 0);
/* ... */
}Si ejecutas verás el triángulo rotando:

Root Signature al detalle
¿Te has fijado en la llamada para asignar el valor?
CommandList->SetGraphicsRootConstantBufferView(
0, /* Root Param Index */
ConstantBufferResource->GetGPUVirtualAddress()
);¿Notas algo raro? ¡No estamos pasándole el descriptor! En vez de eso, le estamos pasando directamente la dirección en memoria del recurso.
Este hecho suscita algunas preguntas:
- Si no estamos usando nuestro descriptor (alojado en ConstantBufferDescriptorHeap), ¿para qué hemos creado un descriptor heap?
- ¿Para qué hemos creado un descriptor si no lo vamos a usar?
- Siempre hemos dicho que en los registros se cargan descriptores, por eso los necesitábamos crear, ¿por qué en este caso no le estamos pasando un descriptor?
La respuesta es la siguiente: un Root Signature tiene espacio reservado para funcionar como un descriptor heap de tipo D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV. ¡Boom!
Es decir, la llamada del código anterior en realidad está creando un descriptor directamente dentro del propio Root Signature.
Estamos usando una parte del Root Signature como un descriptor heap.
¿Entonces para qué hemos creado un descriptor heap aparte? Para no introducir todos los conceptos de golpe y porque lo vamos a usar enseguida para ilustrar otro uso del root signature. Pero efectivamente en este caso no hubiera sido necesario.
Un root signature funciona como un descriptor heap para CBV, SVR y UAV. Además de ello también reserva espacio para almacenar static samplers (para las texturas) y también tiene espacio para almacenar constantes.
Además de contener descriptores, static samplers y constantes, puede almacenar descriptor table. Enseguida veremos que son.
La siguiente imagen ilustra un root signature.
Este root signature ilustrado en la imagen contiene siete parámetros (de 0 a 6). Podemos encontrar parámetros que almacenan descriptores (parámetros con índices 0, 1 y 2), tres parámetros que almacenan descriptor tables (parámetros con índices 3, 4 y 6) y un parámetro que almacena una constante (parámetro 5).
En el caso de nuestro proyecto, DemoApp, tenemos una root signature con un sólo parámetro que almacena un descriptor de tipo CBV.
Vamos a ilustrar en código como podemos definir la root signature de la imagen. De este modo podemos tener una visión más global de cómo funciona una root signature.
D3D12_ROOT_PARAMETER RootParameters[7];Como primer parámetro del root signature un descriptor CBV. ¡El propio root signature está funcionando como un descriptor heap!. Este descriptor, según el diagrama, se debe cargar en el registro b0.
RootParameters[0].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
RootParameters[0].ParameterType = D3D12_ROOT_PARAMETER_TYPE_CBV; // se cargará en algún registro b, ¿cuál? el que indique shader register
RootParameters[0].Descriptor.RegisterSpace = 0; // [*]
RootParameters[0].Descriptor.ShaderRegister = 0; // b0[*] En la ilustración indica espacio 1 porque
se supone que está usando un shader antiguo por
temas de retrocompatibilidad, en la doc oficial de DX12
encontraras más información del problema de compatibilidad
que intenta resolver el campo RegisterSpace.Nosotros usaremos siempre RegisterSpace = 0.
El segundo argumento es un descriptor de tipo SRV. Se carga en el registro t0.
RootParameters[1].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
RootParameters[1].ParameterType = D3D12_ROOT_PARAMETER_TYPE_SRV; // register t
RootParameters[1].Descriptor.RegisterSpace = 0;
RootParameters[1].Descriptor.ShaderRegister = 0; // t0El tercer argumento es un descriptor de tipo UAV (unordered access view). Se carga en el registro u0.
RootParameters[2].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
RootParameters[2].ParameterType = D3D12_ROOT_PARAMETER_TYPE_UAV; // // register u
RootParameters[2].Descriptor.RegisterSpace = 0;
RootParameters[2].Descriptor.ShaderRegister = 0; // u0Los recursos de tipo UNORDERED_ACCESSS_VIEW (UAV) son para escribir en texturas desde el propio shader. No son habituales.
El cuarto, quinto y séptimo argumento son descriptor tables. Lo veremos enseguida.
El sexto argumento es una contante que se carga en el registro b9.
RootParameters[5].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL; // register b
RootParameters[5].ParameterType = D3D12_ROOT_PARAMETER_TYPE_32BIT_CONSTANTS;
RootParameters[5].Descriptor.RegisterSpace = 0;
RootParameters[5].Descriptor.ShaderRegister = 9; // b9Obviando los parámetros asociados a los descriptor tables, el shader quedaría así:
cbuffer SomeConstants : register(b0)
{
float4x4 MVP;
float3 LightDir;
float3 AlbedoColor;
};
Texture2D foo : register(t0);
RWBuffer dataLog : register(u0);
int boo : register(b9);
float4 VSMain(...)
{
// ...
}
float4 PSMain(...) : SV_Target
{
// ...
}Descriptor Tables
Una de las preguntas que puedes estar haciéndote es, si el root signature ya funciona como un descriptor heap para CBV, SRV y UAV, ¿para qué querríamos crear nuestro propio descriptor heap de tipo D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV? ¡Usemos directamente el root signature como descriptor heap!
Bueno no es tan fácil. Un Root Signature solo puede contener un número muy limitado de parámetros.
En concreto, un Root Signature está limitado a un tamaño de 64 DWORDs (1 DWORD = 32 bits).
Almacenar una constante cuesta 1 DWORD por cada constante.
Almacenar un descriptor cuesta 2 DWORD por cada descriptor.
¿Y si queremos usar más descriptores? Entonces usamos un descriptor table.
Un descriptor table hace de puente entre el root signature y los descriptores de un descriptor heap. Cada descriptor table ocupa 1 DWORD en el root signature.
Un descriptor table puede referenciar varios descriptores de un descriptor heap.
Repasa la ilustración anterior y definamos el cuarto argumento:
D3D12_DESCRIPTOR_RANGE DescriptorRanges[3];
DescriptorRanges[0].BaseShaderRegister = 0; // b0
DescriptorRanges[0].NumDescriptors = 1;
DescriptorRanges[0].OffsetInDescriptorsFromTableStart = 0;
DescriptorRanges[0].RangeType = D3D12_DESCRIPTOR_RANGE_TYPE_CBV;
DescriptorRanges[0].RegisterSpace = 0;
DescriptorRanges[1].BaseShaderRegister = 1; // u1, u2
DescriptorRanges[1].NumDescriptors = 2;
DescriptorRanges[1].OffsetInDescriptorsFromTableStart = D3D12_DESCRIPTOR_RANGE_OFFSET_APPEND;
DescriptorRanges[1].RangeType = D3D12_DESCRIPTOR_RANGE_TYPE_UAV;
DescriptorRanges[1].RegisterSpace = 0;
DescriptorRanges[2].BaseShaderRegister = 1; // t1+
DescriptorRanges[2].NumDescriptors = UINT_MAX;
DescriptorRanges[2].OffsetInDescriptorsFromTableStart = D3D12_DESCRIPTOR_RANGE_OFFSET_APPEND;
DescriptorRanges[2].RangeType = D3D12_DESCRIPTOR_RANGE_TYPE_SRV;
DescriptorRanges[2].RegisterSpace = 0;
D3D12_ROOT_PARAMETER RootParameters[7];
/* ... */
RootParameters[3].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
RootParameters[3].ParameterType = D3D12_ROOT_PARAMETER_TYPE_DESCRIPTOR_TABLE;
RootParameters[3].DescriptorTable.NumDescriptorRanges = 3;
RootParameters[3].DescriptorTable.pDescriptorRanges = DescriptorRanges;
/* ... */En nuestro ejemplo con DemoApp podemos usar el descriptor heap que creamos anteriormente usando un descriptor table.
Para ello modifica el método CreateRootSignature tal que así:
void DemoApp::CreateRootSignature()
{
D3D12_DESCRIPTOR_RANGE DescriptorRanges[1];
DescriptorRanges[0].BaseShaderRegister = 0;
DescriptorRanges[0].NumDescriptors = 1;
DescriptorRanges[0].OffsetInDescriptorsFromTableStart = 0;
DescriptorRanges[0].RangeType = D3D12_DESCRIPTOR_RANGE_TYPE_CBV;
DescriptorRanges[0].RegisterSpace = 0;
D3D12_ROOT_PARAMETER RootParameters[1];
RootParameters[0].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
RootParameters[0].ParameterType = D3D12_ROOT_PARAMETER_TYPE_DESCRIPTOR_TABLE;
RootParameters[0].DescriptorTable.NumDescriptorRanges = 1;
RootParameters[0].DescriptorTable.pDescriptorRanges = DescriptorRanges;
D3D12_ROOT_SIGNATURE_DESC SignatureDesc{};
SignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT;
SignatureDesc.NumParameters = _countof(RootParameters);
SignatureDesc.pParameters = RootParameters;
SignatureDesc.NumStaticSamplers = 0;
ComPtr<ID3DBlob> Signature;
ComPtr<ID3DBlob> Error;
D3D12SerializeRootSignature(&SignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1_0, &Signature, &Error);
Device->CreateRootSignature(0, Signature->GetBufferPointer(), Signature->GetBufferSize(), IID_PPV_ARGS(&RootSignature));
}Para asignar un valor al descriptor table debemos usar el siguiente comando:
CommandList->SetGraphicsRootDescriptorTable(
0, /* RootParameterIndex */,
ConstantBufferDescriptorHeap->GetGPUDescriptorHandleForHeapStart() /* BaseDescriptor */
);Sin embargo, previamente debemos indicarle a la GPU que descriptors heaps vamos a usar:
ID3D12DescriptorHeap* Heaps[] { ConstantBufferDescriptorHeap.Get() };
CommandList->SetDescriptorHeaps(
1 /* NumDescriptorHeaps */,
Heaps /* DescriptorHeaps */
);El código final quedaría:
void DemoApp::RecordCommandList()
{
/* ... */
ID3D12DescriptorHeap* Heaps[] { ConstantBufferDescriptorHeap.Get() };
CommandList->SetDescriptorHeaps(
1 /* NumDescriptorHeaps */,
Heaps /* DescriptorHeaps */
);
CommandList->SetGraphicsRootDescriptorTable(
0, /* RootParameterIndex */,
ConstantBufferDescriptorHeap->GetGPUDescriptorHandleForHeapStart() /* BaseDescriptor */
);
CommandList->DrawInstanced(3, 1, 0, 0);
/* ... */
}Si ejecutas volverías a ver el triángulo rotando.
Pipeline con Root Signature
Con todo lo visto hasta ahora esta imagen es muy ilustrativa y da una visión global y completa del pipeline y la root signature:
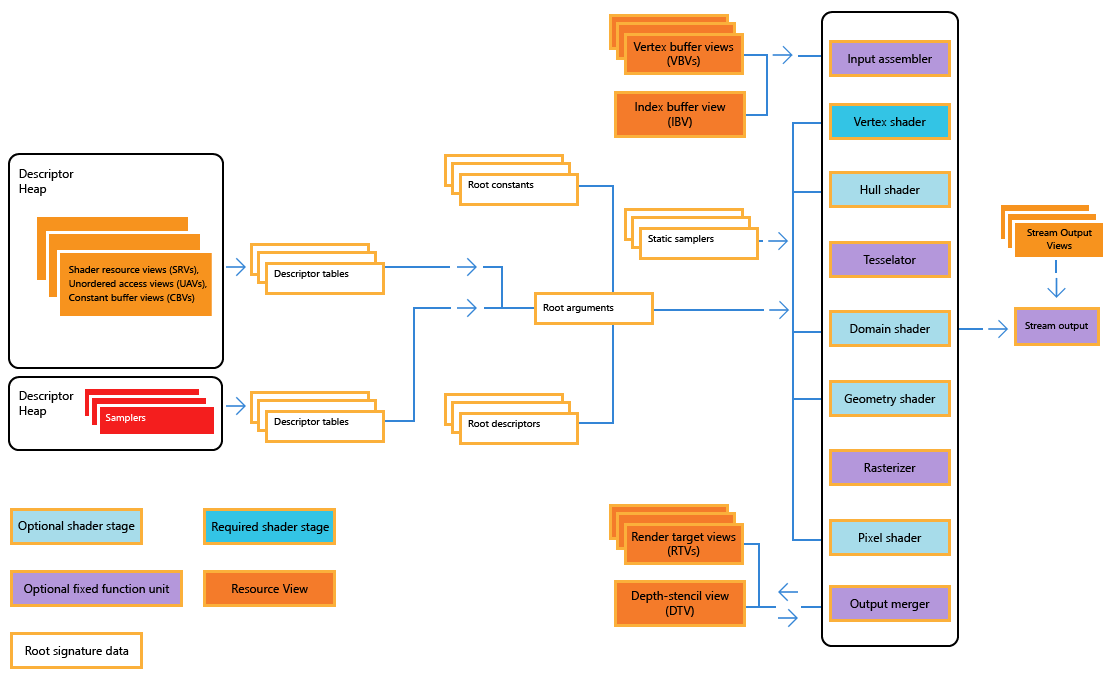
En siguientes tutoriales texturizaremos el triángulo y hablaremos de los samplers.
Código fuente
Puedes descargar el proyecto con el código fuente completo aquí.
Texturas
Vamos a texturizar el triángulo. Para ello cargaremos una textura, creamos los recursos asociados, como los samplers, y se lo pasaremos a los shaders.
Añadir UVs
Cambiar definición de los vértices:
struct Vertex
{
XMFLOAT3 Position;
XMFLOAT2 UV;
XMFLOAT4 Color;
};Asignar las UVs:
Vertex Vertices[] = {
// { POS, UV, COLOR }
{ { 0.0f, 0.5f, 0.0f }, { 0.5f, 1.0f }, { 1.0f, 1.0f, 1.0f, 1.0f } },
{ { 0.5f, -0.5f, 0.0f }, { 1.0f, 0.0f }, { 1.0f, 1.0f, 1.0f, 1.0f } },
{ { -0.5f, -0.5f, 0.0f }, { 0.0f, 0.0f }, { 1.0f, 1.0f, 1.0f, 1.0f } }
};Cambiar el Input Layout:
/* Input Layout */
// vamos a usar un Vertex con position, uv y color
D3D12_INPUT_ELEMENT_DESC pInputElementDescs[] = {
// SemanticName; SemanticIndex; Format; InputSlot; AlignedByteOffset; InputSlotClass; InstanceDataStepRate;
{"POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0},
{"UV", 0, DXGI_FORMAT_R32G32_FLOAT, 0, 4 * 3, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0},
{"COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 0, 4 * (3 + 2), D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0}
};
D3D12_INPUT_LAYOUT_DESC InputLayout{};
InputLayout.NumElements = _countof(pInputElementDescs);
InputLayout.pInputElementDescs = pInputElementDescs;Modifica el shader:
cbuffer SomeConstants : register(b0)
{
float4x4 MVP;
}
struct VS2PS
{
float4 position : SV_Position;
float2 uv : UV0;
float4 color : COLOR;
};
VS2PS VSMain(float3 position : POSITION, float2 uv : UV0, float4 color : COLOR)
{
VS2PS vs2ps;
vs2ps.position = mul(MVP, float4(position, 1.0));
vs2ps.uv = uv;
vs2ps.color = color;
return vs2ps;
}
float4 PSMain(VS2PS vs2ps) : SV_Target
{
return float4(vs2ps.uv, 0.0, 1.0);
}El resultado sería el siguiente:
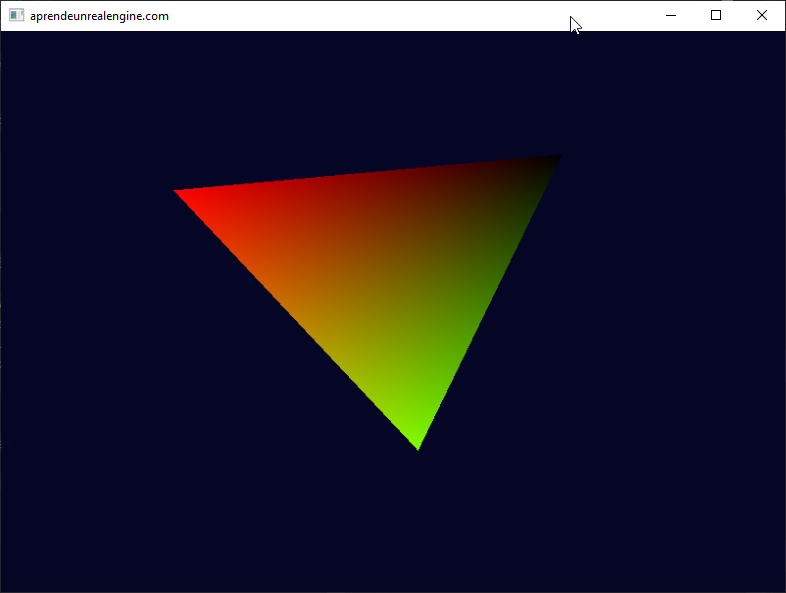
Crear el recurso
Vamos a ampliar la clase GPUMem que creamos en el tutorial sobre recursos.
En concreto, añadir el método Texture2D a la clase GPUMem para crear un recurso de tipo textura:
// GPUMem.h
class GPUMem {
// ...
static ComPtr<ID3D12Resource> Texture2D(
ID3D12Device* Device,
SIZE_T Width,
SIZE_T Height,
DXGI_FORMAT Format
);
// ...
};// GPUMem.cpp
ComPtr<ID3D12Resource> GPUMem::Texture2D(
ID3D12Device* Device,
SIZE_T Width,
SIZE_T Height,
DXGI_FORMAT Format
)
{
ComPtr<ID3D12Resource> Resource;
D3D12_RESOURCE_DESC ResourceDesc{};
ResourceDesc.Width = Width;
ResourceDesc.Height = Height;
ResourceDesc.DepthOrArraySize = 1;
ResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D;
ResourceDesc.Alignment = D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT;
ResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKNOWN;
ResourceDesc.Flags = D3D12_RESOURCE_FLAG_NONE;
ResourceDesc.MipLevels = 1;
ResourceDesc.SampleDesc.Count = 1;
ResourceDesc.SampleDesc.Quality = 0;
ResourceDesc.Format = Format;
D3D12_HEAP_PROPERTIES HeapProps{};
HeapProps.Type = D3D12_HEAP_TYPE_DEFAULT;
Device->CreateCommittedResource(
&HeapProps,
D3D12_HEAP_FLAG_NONE,
&ResourceDesc,
D3D12_RESOURCE_STATE_COPY_DEST,
nullptr,
IID_PPV_ARGS(&Resource)
);
return Resource;
}Imagina por un momento que hemos cargado la textura (la hemos leído de un fichero de imagen).
La primera tentación sería hacer tal y como hemos venido haciendo hasta ahora con los recursos, esto es:
- Crear el recurso en UPLOAD para poder copiar los datos de la textura.
- Usar los métodos Map y Unmap del recurso alojado en UPLOAD para copiar los datos de la textura en memoria de la GPU.
- Recomendable pero opcional: crear el recurso en DEFAULT y, a través de comandos, que la GPU copie de UPLOAD a DEFAULT.
Sin embargo, las tarjetas gráficas tienen una serie de requisitos para poder trabajar con las texturas. Uno de ellos es que ¡las texturas solo se pueden crear en DEFAULT!
Por tanto, el paso 3 que era recomendado pero opcional cuando trabajamos con textura es un paso obligatorio.
No solo eso, en UPLOAD no podemos crear un recurso de tipo textura, hay que usar un recurso de tipo buffer.
El nuevo modo de proceder sería:
- Crear un recurso buffer en UPLOAD. Copiar los datos de la textura a este recurso usando el método Map.
- Crear un recurso textura en DEFAULT.
- La GPU, mediante comandos, debe copiar el recurso de UPLOAD a DEFAULT.
El paso 3 no es tan trivial como en anteriores tutoriales que usábamos el comando CopyResource ¡aquí no podemos copiar los recursos tal cuál porque son de distinto tipo (buffer vs textura)!
Hay que usar otro comando, en concreto CopyTextureRegion.
Copiar una textura
Para copiar una textura se usa el comando CopyTextureRegion.
Recuerda que una textura puede tener subrecursos, por ejemplo mipmapping. También podemos copiar porciones (regiones) de la textura.
Es por ello que el comando CopyTextureRegion no toma un recurso como un todo, como ocurría con el comando CopyResource, si no una estructura indicando una subregión y subrecurso.
ID3D12CommandList::CopyTextureRegion(
D3D12_TEXTURE_COPY_LOCATION* DestinoCopia, // recurso + subrecurso
DstX, DstY, DstZ, // subregion destino
D3D12_TEXTURE_COPY_LOCATION* CopiarDesde, // recurso + subrecurso
D3D12_BOX* SrcBox, // subregion origen
);La estructura D3D12_TEXTURE_COPY_LOCATION contiene una referencia a un recurso y un índice identificando el subrecurso:
D3D12_TEXTURE_COPY_LOCATION DestinoCopia{};
DestinoCopia.Type = D3D12_TEXTURE_COPY_TYPE_SUBRESOURCE_INDEX;
DestinoCopia.SubresourceIndex = 0;
DestinoCopia.pResource = TextureResource.Get(); // en DEFAULTPero también sirve para interpretar como copiar un recurso. En nuestro caso, tenemos que copiar un buffer a una textura. El byte en la posición i-ésima del buffer ¿en qué componente de qué pixel de la textura destino lo almacenamos? Para saberlo necesitamos datos como ¿cuantos bytes ocupa el ancho, cuanto es el alto? etc.,
Al conjunto de datos Depth, Format, Width, Height y RowPitch (tamaño en bytes del ancho de una textura) que permiten saber como copiar un buffer a una textura se le denomina footprint.
D3D12_TEXTURE_COPY_LOCATION CopiarDesde{};
CopiarDesde.Type = D3D12_TEXTURE_COPY_TYPE_PLACED_FOOTPRINT;
CopiarDesde.pResource = UploadBuffer.Get(); // en UPLOAD
CopiarDesde.PlacedFootprint.Footprint.Depth = 1;
CopiarDesde.PlacedFootprint.Footprint.Format = Tex.GetFormat();
CopiarDesde.PlacedFootprint.Footprint.Width = Tex.GetWidth();
CopiarDesde.PlacedFootprint.Footprint.Height = Tex.GetHeight();
CopiarDesde.PlacedFootprint.Footprint.RowPitch = Tex.GetRowPitch();Añade el siguiente código a DemoApp.cpp:
void DemoApp::LoadTexture()
{
TextureLoader Tex(L"texture.png"); // TextureLoader es una clase propia que carga una textura
// Crear el recurso en DEFAULT
TextureResource = GPUMem::Texture2D(Device.Get(), Tex.GetWidth(), Tex.GetHeight(), Tex.GetFormat());
// Descriptor Heap para la textura
// podríamos haber reutilizado la del constantbuffer
// pero vamos a crear otro descriptor heap para
// mayor claridad
D3D12_DESCRIPTOR_HEAP_DESC DescriptorHeapDesc{};
DescriptorHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE;
DescriptorHeapDesc.NumDescriptors = 1;
DescriptorHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV;
Device->CreateDescriptorHeap(&DescriptorHeapDesc, IID_PPV_ARGS(&TextureDescriptorHeap));
// Crear el descriptor
D3D12_SHADER_RESOURCE_VIEW_DESC ResourceViewDesc{};
ResourceViewDesc.ViewDimension = D3D12_SRV_DIMENSION_TEXTURE2D;
ResourceViewDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;
ResourceViewDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
ResourceViewDesc.Texture2D.MipLevels = 1;
Device->CreateShaderResourceView(TextureResource.Get(), &ResourceViewDesc, TextureDescriptorHeap->GetCPUDescriptorHandleForHeapStart());
// Crear el buffer en Upload
SIZE_T SizeInBytes = (Tex.Size() + 256) & ~255;
ComPtr<ID3D12Resource> UploadBuffer = GPUMem::Buffer(Device.Get(), SizeInBytes, D3D12_HEAP_TYPE_UPLOAD);
// Copiar los datos de la textura a upload
UINT8* pData;
UploadBuffer->Map(0, nullptr, reinterpret_cast<void**>(&pData));
memcpy(pData, Tex.Pointer(), Tex.Size());
UploadBuffer->Unmap(0, nullptr);
// Empezamos a grabar comandos para copiar de UPLOAD a DEFAULT
CommandAllocator->Reset();
CommandList->Reset(CommandAllocator.Get(), nullptr);
D3D12_TEXTURE_COPY_LOCATION Dst{};
Dst.Type = D3D12_TEXTURE_COPY_TYPE_SUBRESOURCE_INDEX;
Dst.SubresourceIndex = 0;
Dst.pResource = TextureResource.Get();
D3D12_TEXTURE_COPY_LOCATION Src{};
Src.Type = D3D12_TEXTURE_COPY_TYPE_PLACED_FOOTPRINT;
Src.pResource = UploadBuffer.Get();
Src.PlacedFootprint.Footprint.Depth = 1;
Src.PlacedFootprint.Footprint.Format = Tex.GetFormat();
Src.PlacedFootprint.Footprint.Width = Tex.GetWidth();
Src.PlacedFootprint.Footprint.Height = Tex.GetHeight();
Src.PlacedFootprint.Footprint.RowPitch = Tex.GetRowPitch();
CommandList->CopyTextureRegion(&Dst, 0, 0, 0, &Src, nullptr);
// Una vez copiado, cambiamos el estado del recurso
GPUMem::ResourceBarrier(
CommandList.Get(),
TextureResource.Get(),
D3D12_RESOURCE_STATE_COPY_DEST,
D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE
);
CommandList->Close();
ID3D12CommandList* CommandLists[]{ CommandList.Get() };
CommandQueue->ExecuteCommandLists(_countof(CommandLists), CommandLists);
FlushAndWait();
}No olvides añadir también la declaración en DemoApp.h y llamar al método anterior en el constructor.
DemoApp::DemoApp(HWND hWnd, UINT Width, UINT Height)
{
/* ... */
CreateVertexBuffer();
LoadTexture();
CreateConstantBuffer();
}Cargar la textura
Vamos a usar la siguiente textura (puedes hacer clic con el botón derecho y descargarla)
Hay muchas librerías para cargar ficheros de imagen en memoria y usarlos como textura.
Dado que estamos en Windows usaremos una librería nativa llamada WIC para leer imágenes. Podríamos haber usado otra.
Haciendo uso de la librería WIC vamos a crear la clase TextureLoader:
class TextureLoader
{
public:
TextureLoader(const LPCWSTR& Path);
UINT GetWidth() const { return TextureWidth; }
UINT GetHeight() const { return TextureHeight; }
DXGI_FORMAT GetFormat() const { return Format; }
BYTE* Pointer() const { return ImageData; }
SIZE_T Size() const { return ImageSize; }
SIZE_T GetRowPitch() const { return BytesPerRow; }
private:
int ImageSize;
int BytesPerRow;
LPCWSTR Filename;
UINT TextureWidth;
UINT TextureHeight;
DXGI_FORMAT Format;
BYTE* ImageData;
/* metodos auxiliares */
};Esta clase y su implementación están incluidas en el código fuente de este proyecto disponible más abajo para descargar. No vamos a entrar en detalles de como leer ficheros de imagen (jpg, png, etc.,) y descodificarlo en memoria, usa esta clase como una "caja negra".
Si tienes curiosidad por como se usa WIC tienes la documentación oficial aquí.
El 99% de la clase TextureLoader está tomada de aquí.
Shader con textura
Vamos a modificar nuestro shader para que lea una textura.
Para poder leer una textura se hace uso de una referencia a la propia textura y de un sampler.
Un sampler es un objeto que permite leer una textura. Por ejemplo, un sampler dice que hacer si lees una textura fuera de los límites (por ejemplo coordenada uv (2,1), el tipo de interpolación, etc.,). Aquí tienes algunos ejemplos muy ilustrativos para que puedas hacerte una idea de cómo funciona un sampler.
Nuestro shader quedaría:
// shaders.hlsl
cbuffer SomeConstants : register(b0)
{
float4x4 MVP;
}
Texture2D mainTex : register(t0);
SamplerState samplerTex : register(s0);
struct VS2PS
{
float4 position : SV_Position;
float2 uv : UV0;
float4 color : COLOR;
};
VS2PS VSMain(float3 position : POSITION, float2 uv : UV0, float4 color : COLOR)
{
VS2PS vs2ps;
vs2ps.position = mul(MVP, float4(position, 1.0));
vs2ps.uv = uv;
vs2ps.color = color;
return vs2ps;
}
float4 PSMain(VS2PS vs2ps) : SV_Target
{
float4 col = mainTex.Sample(samplerTex, vs2ps.uv);
return col;
}Toca declarar en el root signature estos usos de los registros t0 y s0.
void DemoApp::CreateRootSignature()
{
// Dos parametros: Un constant buffer para MVP y un descriptor table a la textura
D3D12_ROOT_PARAMETER RootParameters[2];
// Constant Buffer
RootParameters[0].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
RootParameters[0].ParameterType = D3D12_ROOT_PARAMETER_TYPE_CBV;
RootParameters[0].Descriptor.RegisterSpace = 0;
RootParameters[0].Descriptor.ShaderRegister = 0;
// Texture
D3D12_DESCRIPTOR_RANGE TexDescriptorRanges[1];
TexDescriptorRanges[0].BaseShaderRegister = 0;
TexDescriptorRanges[0].NumDescriptors = 1;
TexDescriptorRanges[0].OffsetInDescriptorsFromTableStart = 0;
TexDescriptorRanges[0].RangeType = D3D12_DESCRIPTOR_RANGE_TYPE_SRV;
TexDescriptorRanges[0].RegisterSpace = 0;
RootParameters[1].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
RootParameters[1].ParameterType = D3D12_ROOT_PARAMETER_TYPE_DESCRIPTOR_TABLE;
RootParameters[1].DescriptorTable.NumDescriptorRanges = _countof(TexDescriptorRanges);
RootParameters[1].DescriptorTable.pDescriptorRanges = TexDescriptorRanges;
// Samplers
D3D12_STATIC_SAMPLER_DESC SamplerDesc{};
SamplerDesc.ShaderRegister = 0;
SamplerDesc.RegisterSpace = 0;
SamplerDesc.ShaderVisibility = D3D12_SHADER_VISIBILITY_PIXEL;
SamplerDesc.Filter = D3D12_FILTER_MIN_MAG_MIP_POINT;
SamplerDesc.AddressU = D3D12_TEXTURE_ADDRESS_MODE_BORDER;
SamplerDesc.AddressV = D3D12_TEXTURE_ADDRESS_MODE_BORDER;
SamplerDesc.AddressW = D3D12_TEXTURE_ADDRESS_MODE_BORDER;
SamplerDesc.MipLODBias = 0;
SamplerDesc.MaxAnisotropy = 0;
SamplerDesc.ComparisonFunc = D3D12_COMPARISON_FUNC_NEVER;
SamplerDesc.BorderColor = D3D12_STATIC_BORDER_COLOR_TRANSPARENT_BLACK;
SamplerDesc.MinLOD = 0.0f;
SamplerDesc.MaxLOD = D3D12_FLOAT32_MAX;
// Create Root Signature
D3D12_ROOT_SIGNATURE_DESC SignatureDesc{};
SignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT;
SignatureDesc.NumParameters = _countof(RootParameters);
SignatureDesc.pParameters = RootParameters;
SignatureDesc.NumStaticSamplers = 1;
SignatureDesc.pStaticSamplers = &SamplerDesc;
ComPtr<ID3DBlob> Signature;
ComPtr<ID3DBlob> Error;
D3D12SerializeRootSignature(&SignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1_0, &Signature, &Error);
Device->CreateRootSignature(0, Signature->GetBufferPointer(), Signature->GetBufferSize(), IID_PPV_ARGS(&RootSignature));
}Commands
Ya solo queda cargar la textura concreta en los registros indicados en el root signature:
void DemoApp::RecordCommandList()
{
/* ... */
ID3D12DescriptorHeap* Heaps[]{ TextureDescriptorHeap.Get() };
CommandList->SetDescriptorHeaps(_countof(Heaps), Heaps);
CommandList->SetGraphicsRootDescriptorTable(1, TextureDescriptorHeap->GetGPUDescriptorHandleForHeapStart());
CommandList->DrawInstanced(3, 1, 0, 0);
/* ... */
}Código fuente
Puedes descargar el código completo del proyecto aquí.
Consideraciones
Algunas consideraciones:
- Solo se pueden crear texturas en DEFAULT.
- Es imposible llamar directamente a Map en un recurso textura, porque siempre deben estar en DEFAULT.
- Debes copiar los datos de una textura a un recurso buffer en UPLOAD.
- Debes copiar el buffer que representa la textura en UPLOAD al recurso en DEFAULT.
- Cuando copias subrecursos o recursos de distinto tipo no te vale usar el comando CopyResource. En vez de eso debes usar CopyTextureRegion.
- Para saber que la GPU sepa como copiar un buffer a una textura necesita que declares su footprint.
- Un footprint contiene el ancho, alto, formato y otros campos importantes para que la GPU sepa como copiar un buffer a un subrecurso de una textura.
- Dado que puedes querer copiar solo un subrecurso de una textura a veces es difícil obtener el footprint de un subrecurso, para ello se usa ID3D12Device::GetCopyableFootprints.
- Incluso si vas a usar todo el buffer y por tanto es trivial rellenar la estructura footprint es recomendable seguir usando el método GetCopyableFootprints: para que tenga en cuenta consideraciones acerca del alineamiento (en nuestro proyecto no lo usamos por simplicidad pero sería recomendable su uso).
- Los samplers tienen un campo específico en el Root Signature.